Sur cette page
- Le code généré par IA est-il sûr ?
- Pourquoi tant de code généré par IA est-il non sécurisé ?
- Quels types de vulnérabilités le code IA introduit-il ?
- Que ratent les scanners, et les modèles eux-mêmes ?
- Peut-on faire confiance à une IA pour corriger ses propres vulnérabilités ?
- Comment rendre le code généré par IA sûr ?
- Questions fréquentes
- Le code généré par IA est-il sûr ?
- Est-il sûr de déployer du code généré par IA en production ?
- Pourquoi le code généré par IA est-il non sécurisé si le modèle est si capable ?
- Puis-je simplement demander à l'IA de vérifier elle-même son code pour les vulnérabilités ?
- Quelles sont les vulnérabilités les plus courantes dans le code généré par IA ?
- Comment rendre le code généré par IA sûr ?

Le code généré par IA est-il sûr ? Il s'exécute, il passe la démo, et il ressemble au code qu'un ingénieur compétent aurait écrit. C'est précisément le problème. « Marche » et « sécurisé » sont deux propriétés distinctes, et un agent IA optimise à fond la première tandis qu'un prompt « fais que ça marche » ne demande jamais la seconde. Le résultat, mesuré à répétition par des études indépendantes, c'est qu'une large part du code généré par IA est livrée avec de vraies vulnérabilités. Ce guide vous donne la réponse directe, les données 2026, les classes de vulnérabilités que les scanners et même les modèles qui écrivent le code ratent, et ce qu'il faut réellement pour rendre le code généré par IA sûr à livrer.
Le code généré par IA est-il sûr ?
Non, pas par défaut. Le code généré par IA est aussi sûr que les contrôles qui l'entourent, et la plupart des configurations de code IA n'ont aucun contrôle qui agisse avant que le code n'atterrisse. Le modèle produit de façon fiable du code qui compile et passe le chemin heureux ; il ne produit pas de façon fiable du code qui résiste à un attaquant, car résister à un attaquant tient aux vérifications qui sont absentes, et un prompt qui demande une fonctionnalité opérante ne demande jamais le garde-fou manquant.
Le cadrage honnête, c'est que le code généré par IA n'est pas catégoriquement dangereux, c'est du code non relu produit à une vitesse qu'aucun humain ne peut relire. Un développeur junior écrit du code non sécurisé lui aussi, mais assez lentement pour que la revue suive le rythme. Un agent IA écrit des milliers de lignes par jour, de sorte que l'écart entre « a l'air correct » et « est correct » se creuse plus vite que quiconque ne peut le combler. La question de la sûreté est donc en réalité une question de contrôle : qu'est-ce qui attrape la vulnérabilité, et quand.
du code généré par IA était vulnérable sur les scénarios de sécurité MITRE Top-25 (NYU, Asleep at the Keyboard)
des solutions d'agents de code IA étaient sécurisées, contre 61 % fonctionnellement correctes (Carnegie Mellon SusVibes)
le contrôle d'accès rompu, premier risque du Top 10 OWASP, et une classe que les scanners génériques attrapent rarement
Pourquoi tant de code généré par IA est-il non sécurisé ?
Parce que le modèle reproduit la moyenne de ses données d'entraînement, et la moyenne du code public n'est pas sécurisée. Trois forces se cumulent, et aucune n'est résolue par un meilleur modèle.
D'abord, le problème du corpus. Le modèle a appris sur un immense ensemble de code public truffé des classiques OWASP : SQL concaténé par chaînes, vérifications d'autorisation manquantes, crypto faible, secrets en ligne. Le non-sécurisé-par-défaut est son a priori statistique, alors il attrape le motif courant, et le motif courant est fréquemment celui qui n'est pas sûr.
Ensuite, le problème de l'absence. La sécurité est d'ordinaire un garde-fou présent : une vérification de bornes, une vérification de propriété, une entrée échappée. Un modèle à qui l'on demande un résultat positif (« ajoute un endpoint de paiement ») n'ajoute pas un garde-fou négatif que personne n'a demandé. La fonctionnalité marche précisément parce que la vérification manquante n'affecte pas le chemin heureux.
Enfin, le problème du lecteur, et c'est le décisif. La personne qui écrit le prompt peut dire si la fonctionnalité marche. Elle ne peut souvent pas dire si elle est sûre. Cet écart, entre l'intention de l'auteur et la capacité du relecteur, c'est tout le problème de sécurité, et c'est exactement ce qui se creuse quand un non-spécialiste vibe-code une fonctionnalité dans un paragraphe d'intention. Nous approfondissons cela dans la sécurité du vibe coding.
Quels types de vulnérabilités le code IA introduit-il ?
Les mêmes que les humains introduisent, reproduites plus vite que la revue ne peut suivre. Voici les classes qui reviennent dans chaque étude et chaque outil, chacune rattachée à l'endroit où nous la traitons en profondeur :
- Injection (CWE-89, CWE-78). SQL et commandes shell concaténés à partir d'entrées utilisateur, parce que le modèle les a appris d'un corpus qui en regorge. Voyez pourquoi la plupart des constats SAST sont du bruit pour comprendre pourquoi seuls les atteignables comptent.
- Autorisation rompue et IDOR (CWE-862, CWE-639). L'agent construit l'endpoint qui renvoie l'enregistrement mais rarement la vérification que l'appelant en est propriétaire. C'est le risque numéro un d'OWASP et celui que les scanners voient le moins.
- Secrets en dur (CWE-798). Sommé de fournir une intégration opérante, le modèle met en ligne une clé d'API ou un mot de passe pour que le code tourne du premier coup, et le secret vit ensuite dans le dépôt et dans chaque fork.
- Validation d'entrée manquante (CWE-20). Les endpoints générés font confiance à leurs entrées, ce qui est l'activateur discret de l'injection et de la désérialisation en aval.
- Désérialisation non sécurisée (CWE-502). « Charge l'objet enregistré » devient
pickleouyaml.loadsur des octets non fiables, transformant un blob stocké en exécution de code à distance. - Failles de logique métier. La classe la plus dangereuse, car aucun scanner n'est taillé pour l'attraper : un panier à quantité négative, un coupon qui se cumule, un remboursement qui saute la vérification de propriété. Le code est syntaxiquement parfait et sémantiquement faux. C'est notre analyse approfondie des failles de logique métier dans le code généré par IA.
Que ratent les scanners, et les modèles eux-mêmes ?
Deux angles morts comptent le plus, et ils expliquent pourquoi « lance simplement un scanner » et « demande au modèle de vérifier son propre travail » échouent tous deux.
Le premier, c'est la logique métier. Un analyseur statique raisonne sur des motifs de code ; une règle métier (« seul le propriétaire peut modifier ce document », « la quantité doit être positive ») vit hors du code, dans votre domaine. Il n'y a aucune entrée corrompue ni aucun point d'exécution dangereux à faire correspondre, juste une instruction if qui n'a jamais été écrite, de sorte que le scanner rapporte le fichier comme propre alors qu'il est pleinement exploitable.
Le second, c'est le modèle qui corrige sa propre copie. Demander au même agent qui a écrit le code de le relire hérite des mêmes angles morts : il ne connaît pas votre modèle d'autorisation, il ne peut pas voir les autres constats autour de la ligne, et il est aussi sûr de la version non sécurisée que de la version sécurisée. Les tests indépendants le confirment, seule une petite fraction des solutions IA sont sécurisées même quand la plupart sont fonctionnellement correctes. Une vérification digne de confiance a besoin d'un signal extérieur : une analyse consciente de l'atteignabilité qui suit le flux de données réel, et vos propres règles chargées comme vérité de terrain, pas l'opinion du modèle.
La question n'est pas de savoir si l'IA écrit du code non sécurisé, tout auteur le fait. Elle est de savoir si quoi que ce soit attrape la ligne non sécurisée avant qu'elle ne soit livrée, et à la vitesse de l'IA le seul endroit où l'attraper, c'est là où la ligne est écrite.
Peut-on faire confiance à une IA pour corriger ses propres vulnérabilités ?
Vous pouvez faire confiance à un agent IA pour appliquer une correction bien plus que pour décider ce qui est une vulnérabilité réelle et atteignable. Le modèle est fort pour réécrire une ligne une fois qu'il sait précisément quoi changer ; il est faible pour juger si un problème est exploitable, ce qu'un scanner mûr a justement déjà calculé. La posture digne de confiance n'est donc pas « IA, sécurise mon code », c'est « donne à l'agent des constats confirmés et classés par atteignabilité plus tes règles, laisse-le les corriger, et approuve chaque diff ». Nous couvrons cette boucle dans la remédiation des vulnérabilités par IA et dans la question de savoir si un agent peut trouver et corriger les vulnérabilités automatiquement.
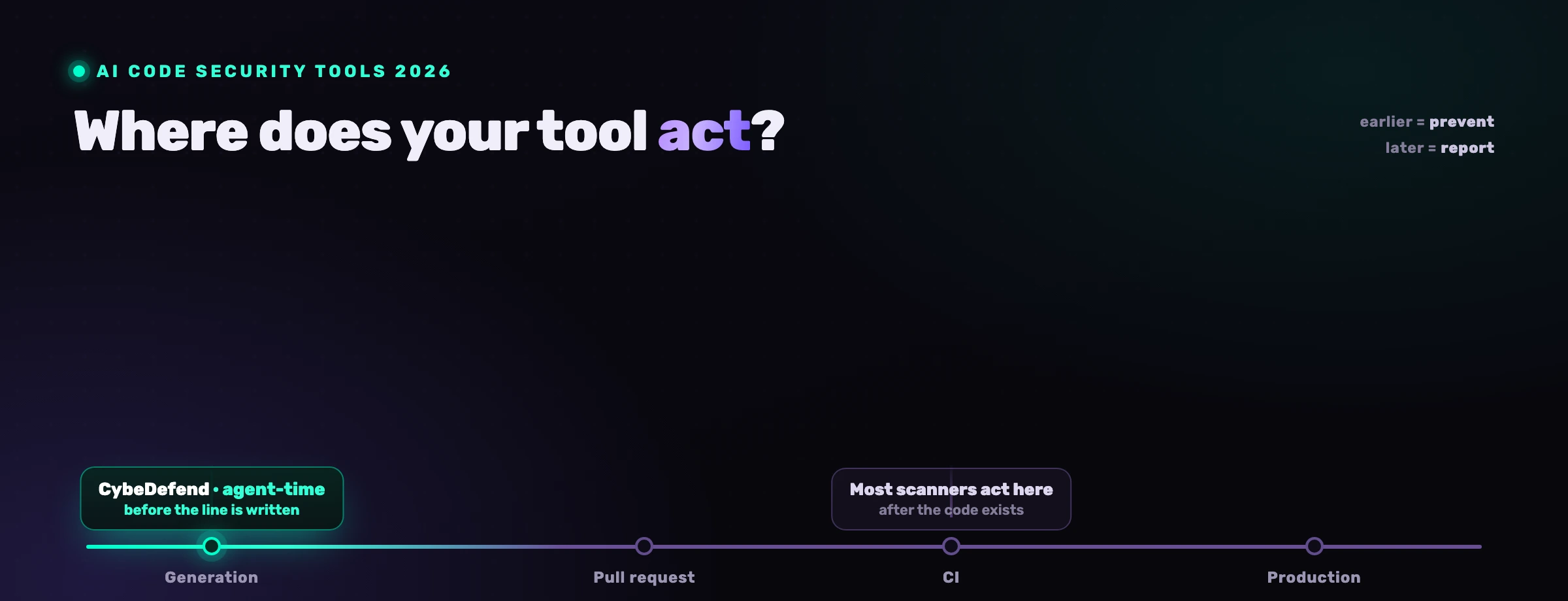
Comment rendre le code généré par IA sûr ?
Vous le rendez sûr en déplaçant le contrôle au moment où le code est écrit, au lieu de faire confiance au modèle ou d'attendre un scanner après la fusion. Trois mouvements, par ordre de levier :
- Gouverner au moment de la génération. Chargez vos règles de sécurité et métier dans l'agent avant chaque modification, de sorte que le motif sûr soit le défaut qu'il attrape. La vulnérabilité jamais écrite n'a besoin d'aucun tri. C'est l'idée centrale de la sécurité des agents de code IA.
- Analyser en continu et renvoyer les constats à l'agent. Gardez en marche le SAST conscient de l'atteignabilité, le SCA, les secrets, l'IaC et le reste, et mettez leurs constats confirmés entre les mains de l'agent pour qu'il remédie les vrais dans la boucle.
- Garder la CI et la revue humaine en filet de sécurité. Une barrière SAST sur chaque pull request et un humain qui approuve les diffs attrapent ce qui passe. Ils sont nécessaires, mais à la vitesse de l'IA ils ne peuvent pas être la seule ligne.
La version pratique complète, c'est comment ajouter de la sécurité à votre workflow de code IA et comment sécuriser toute une application en cinq minutes.
VibeDefend est la couche qui fait les deux premiers. C'est un CLI npm gratuit qui s'installe en quelques secondes et câble Claude Code, Cursor, Windsurf, OpenAI Codex et VS Code Copilot dans quatre couches de gouvernance à l'intérieur de la boucle de l'agent.

Trois couches gouvernent ce que l'agent écrit : les Business Rules extraites de votre dépôt, les Security Rules issues d'OWASP, SOC 2, RGPD et ISO 27001, et un Action Guard qui bloque les appels destructeurs. La quatrième, Live Findings, câble l'agent dans la plateforme AppSec complète de CybeDefend, huit scanners tournant en continu avec chaque constat en direct dans le contexte de l'agent, de sorte que l'agent n'écrit pas seulement du code plus sûr, il corrige les vulnérabilités que vous avez déjà. Rien de votre code ne traverse le réseau ; seules des métadonnées de gouvernance structurées le font, sur des tenants UE ou US physiquement séparés.
Questions fréquentes
Le code généré par IA est-il sûr ?
Pas par défaut. Le code généré par IA s'exécute de façon fiable et passe le chemin heureux, mais les tests indépendants constatent à répétition qu'une large part en est non sécurisée, environ 40 % de vulnérable dans l'étude NYU « Asleep at the Keyboard », et seulement 10 % environ des solutions d'agents de code IA sécurisées dans le benchmark SusVibes de Carnegie Mellon, alors même que la plupart étaient fonctionnellement correctes. Il devient sûr quand vous ajoutez un contrôle qui agit là où le code est écrit et gardez la revue humaine et l'analyse en CI derrière lui.
Est-il sûr de déployer du code généré par IA en production ?
Seulement après qu'il a été relu et analysé comme tout code devrait l'être, et idéalement après avoir été gouverné au moment où il était écrit. Déployer du code IA droit depuis « ça marche » est risqué parce que les failles (autorisation manquante, injection, secrets en dur, erreurs de logique métier) n'affectent pas le chemin heureux et survivent donc à un test fonctionnel. Mettez-le sous barrière avec un SAST conscient de l'atteignabilité en CI, une revue humaine des chemins sensibles à la sécurité, et un contrôle au moment du prompt pour que la version sûre soit écrite en premier.
Pourquoi le code généré par IA est-il non sécurisé si le modèle est si capable ?
Parce que la capacité à produire du code opérant n'est pas la même chose que produire du code sécurisé. Le modèle reproduit les motifs non sécurisés courants dans ses données d'entraînement publiques, la sécurité est d'ordinaire un garde-fou qu'il faut ajouter plutôt qu'un résultat positif demandé par un prompt, et la personne qui écrit le prompt ne peut souvent pas évaluer si le résultat est sûr. Rien de tout cela n'est résolu par un modèle plus intelligent ; cela se résout par un contrôle autour du modèle.
Puis-je simplement demander à l'IA de vérifier elle-même son code pour les vulnérabilités ?
Cela aide un peu et n'est pas suffisant. Le même modèle qui a écrit le code partage ses angles morts : il ne connaît pas votre modèle d'autorisation ni votre délimitation de tenant, il ne peut pas voir les autres constats autour de la ligne, et il est tout aussi sûr de la version non sécurisée que de la sécurisée. Une vérification digne de confiance a besoin d'un signal extérieur, une analyse consciente de l'atteignabilité et vos propres règles comme vérité de terrain, pas l'auto-évaluation du modèle.
Quelles sont les vulnérabilités les plus courantes dans le code généré par IA ?
L'injection (CWE-89, CWE-78), l'autorisation rompue et l'IDOR (CWE-862, CWE-639), les secrets en dur (CWE-798), la validation d'entrée manquante (CWE-20), la désérialisation non sécurisée (CWE-502), et les failles de logique métier. Les cinq premières sont détectables par de bons scanners quand vous filtrez par atteignabilité ; la dernière, la logique métier, est la dangereuse parce qu'aucun scanner n'est taillé pour attraper une règle syntaxiquement parfaite et sémantiquement fausse.
Comment rendre le code généré par IA sûr ?
Déplacez le contrôle au moment de la génération : chargez vos règles de sécurité et métier dans l'agent pour qu'il écrive le motif sûr en premier, analysez en continu et renvoyez les constats confirmés à l'agent pour qu'il remédie, et gardez une barrière SAST en CI plus la revue humaine en filet de sécurité. Faire confiance au modèle pour s'auto-surveiller, ou ne compter que sur une analyse post-fusion qui arrive après que l'agent est passé à autre chose, c'est ce qui laisse l'écart.