Sur cette page
- What is a business logic flaw?
- Why can't SAST find business logic flaws?
- Why do AI coding agents produce more of them?
- What do business logic flaws in AI code look like?
- How do you catch business logic flaws at agent-time?
- How is this different from SAST and SCA?
- Frequently asked questions
- What is a business logic flaw in simple terms?
- Why can't SAST or SCA catch business logic vulnerabilities?
- Why do AI coding agents produce more business logic flaws?
- What are the most common business logic flaws in AI-generated code?
- How do you prevent business logic flaws instead of just detecting them?
- Does this replace my SAST and SCA scanner?
- How does VibeDefend know my business rules without reading my code?
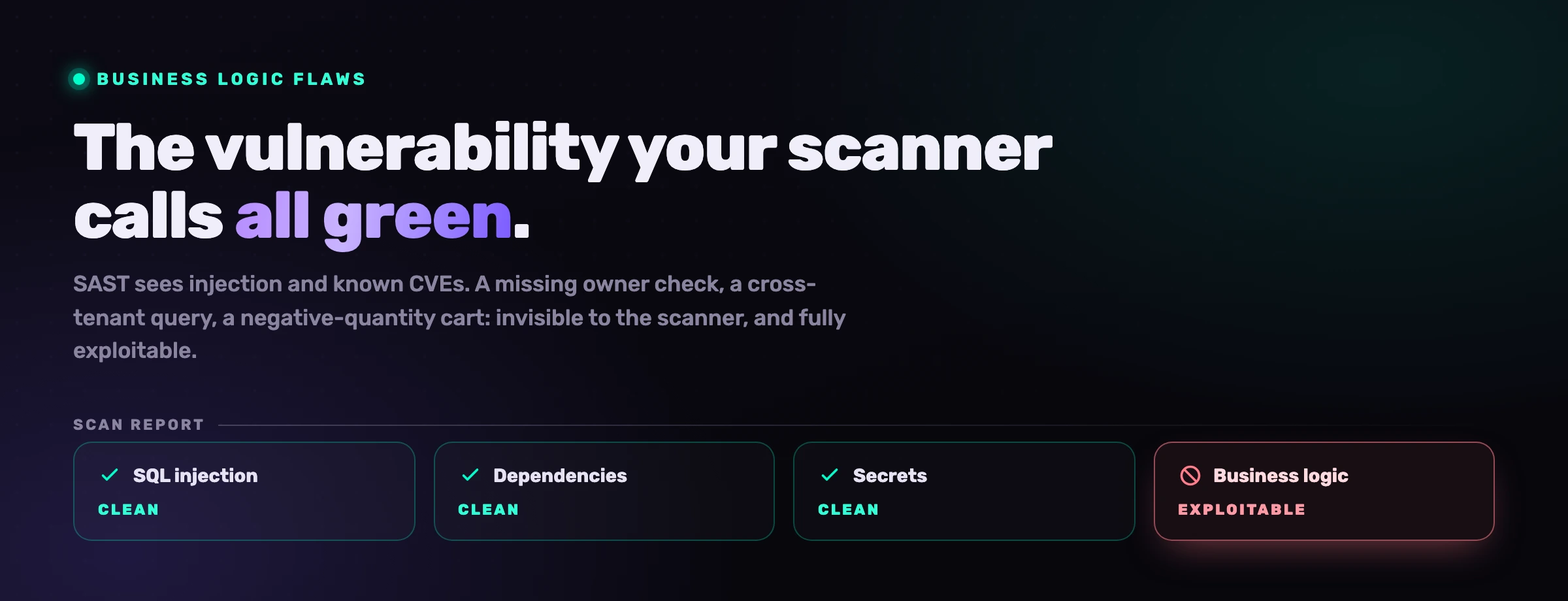
Your SAST scanner can find a SQL injection in a string it has never seen before. It cannot tell you that your new checkout endpoint lets a customer set a negative quantity and walk out with money. The first is a syntax pattern. The second is a business rule, and your scanner was never told what your business rules are. AI coding agents make this gap worse, because they generate plausible code that pattern-matches the framework perfectly while quietly breaking the rule that matters.
What is a business logic flaw?
A business logic flaw is a vulnerability where the code is syntactically correct, free of injection, and built on patched libraries, yet it violates a rule your application is supposed to enforce. The classic examples are broken authorization, missing tenant scoping, integer or quantity abuse, insecure direct object references (IDOR) and order-of-operations races. Nothing is malformed. The logic is just wrong about what is allowed.
This is the category OWASP tracks as Business Logic Vulnerabilities and, for the authorization slice, as Broken Access Control, the number-one risk in the OWASP Top 10. These flaws are dangerous precisely because they look like normal traffic. There is no malformed payload, no stack trace, no signature for an intrusion detection system to match. The request is well-formed; it simply should not have been honored. We walked through one end to end in the $0 cart: a perfect CI/CD pipeline, every dashboard green, and an entire inventory checked out for nothing.
Why can't SAST find business logic flaws?
Because SAST reasons about code, and a business rule lives outside the code. A static analyzer can follow tainted data from a source to a sink and prove an injection is reachable. It has no source for the fact that "only the owner of a document may edit it" or "quantity must be a positive integer." Those rules are in your head, your tickets and your domain, not in any pattern the scanner ships with.
This is a structural limit, not a maturity gap that a newer scanner closes. SAST excels at taint analysis: untrusted input, dangerous sink, no sanitizer in between. A missing authorization check is the opposite shape. There is no tainted input and no dangerous sink, just an if statement that was never written. You cannot pattern-match the absence of a rule you were never given. That is also why most teams drown in scanner output that misses the real risk, the subject of why most SAST findings are noise. The right mental model is an iceberg.
- Injection: SQL, command, XSS, SSRF, with a clear source-to-sink path
- Known CVEs in third-party dependencies (SCA)
- Hardcoded secrets and obvious misconfiguration
Quantity and money abuse
Negative or zero quantity, float rounding, a price recomputed to zero at checkout.
Broken authorization
An update or delete route that never checks the caller actually owns the record.
IDOR
Swapping an id in the URL to read or mutate an object that belongs to someone else.
Missing tenant scope
A query filtered by id but not by tenant, returning another customer's rows.
Everything below the waterline passes a clean SAST and SCA run. The code compiles, the libraries are current, no injection is reachable. The report is all green, and the application is exploitable.
Why do AI coding agents produce more of them?
Because an AI agent is a pattern-matcher trained on the shape of working code, and a business rule is not a shape. When you ask an agent to "add an endpoint to update a project," it produces a handler that parses the id, loads the row and saves the change, because that is what millions of correct-looking handlers do. It has no reason to add an owner check or a tenant filter, since those are specific to your domain and absent from the generic pattern.
So the flaw is not a bug the model introduces by accident; it is the predictable result of generating the average of all similar code. The average update endpoint on the internet does not enforce your authorization model. Worse, the output is fluent and confident, which is exactly what makes it pass review. A reviewer skims a handler that looks like every other handler and approves it. At machine speed, agents now generate thousands of lines a day, far more than any human reads end to end, so the gap between "looks right" and "is right" is where the breaches accumulate. We cover the broader risk surface in our guide to AI coding agent security.
A scanner asks, "is this line dangerous?" A business logic flaw answers, "no," and is exploited anyway. The right question is, "does this code follow the rules of this codebase?" and no syntax tool was ever built to answer it.
What do business logic flaws in AI code look like?
They look like clean, idiomatic code with one missing guard. Here are three classes an agent ships routinely. Each compiles, each passes SAST, and each is a critical finding.
Negative-quantity cart. Ask for an "add to cart" endpoint and you get arithmetic with no domain constraint. A quantity of -1 subtracts from the total.
// Vulnerable: no constraint on quantity
function addToCart(cart, item, quantity) {
cart.total += item.price * quantity; // quantity = -1 lowers the total
return cart;
}
// Fixed: enforce the business rule
function addToCart(cart, item, quantity) {
if (!Number.isInteger(quantity) || quantity < 1) {
throw new ValidationError("quantity must be a positive integer");
}
cart.total += item.price * quantity;
return cart;
}
Missing authorization / IDOR. Ask for an "update project" route and you get a handler that loads by id and saves. Any authenticated user can pass any id.
# Vulnerable: loads by id, never checks ownership (IDOR)
@app.put("/projects/{project_id}")
def update_project(project_id, body, user):
project = db.get(Project, project_id)
project.name = body.name
db.commit()
return project
# Fixed: require the caller to own the record
@app.put("/projects/{project_id}")
def update_project(project_id, body, user):
project = db.get(Project, project_id)
require_owner(project, user) # 403 if user.id != project.owner_id
project.name = body.name
db.commit()
return project
Missing tenant scope. In a multi-tenant app, a query filtered only by id leaks across tenants.
# Vulnerable: filtered by id only, crosses tenant boundary
invoice = db.query(Invoice).filter(Invoice.id == invoice_id).first()
# Fixed: scope every query to the caller's tenant
invoice = db.query(Invoice).filter(
Invoice.id == invoice_id,
Invoice.tenant_id == user.tenant_id,
).first()
In all three, the difference between safe and exploitable is one line that encodes a rule the agent had no way to know. The negative-quantity case is also a full exploit chain on its own.
How do you catch business logic flaws at agent-time?
You catch them by giving the agent your rules before it writes, not by scanning after it ships. If the agent knows "money uses Decimal, every write goes through requireOwner, every query is scoped to tenant_id" at the moment it generates the handler, it writes the guarded version on the first try. The flaw is never created, so there is nothing to find, triage or fix later.
This is the core move: shift the check left of the keystroke. A post-hoc scanner can only flag what already exists in the diff, which means a human still has to read, understand and reject fluent-looking code under time pressure. Loading the rules into the agent's context turns the rule into a default. The agent stops producing the average endpoint and starts producing your endpoint. For domains where these flaws are most expensive, banking and fintech, agent-time enforcement is the difference between a guard that exists by design and one that depends on a reviewer catching its absence.
How is this different from SAST and SCA?
It is a different layer of the problem. SAST and SCA answer "is this code dangerous or out of date?" Agent-time rule enforcement answers "does this code follow the rules of this codebase?" You want both: keep SAST for injection and taint, keep SCA for vulnerable dependencies, and add a layer that carries your business rules into the moment of generation.
The legacy stack is necessary and not sufficient. It was built for a syntax-shaped problem and remains the right tool for that problem. Business logic flaws are an intent-shaped problem, and they need a layer that knows your intent.
VibeDefend is that layer. It mines the business rules already present in your repository and loads them into your AI coding agent before each edit, so the agent writes code that respects your authorization, money and tenant rules from the first keystroke. It is a free npm CLI and installs in about five seconds.

The Business Rules layer is mined from your own repository, use Decimal for money, route every write through requireOwner, scope every query to the tenant, and gets loaded into the agent before each edit. The privacy model is strict: nothing about your code crosses the wire, only governance metadata, and EU and US tenants are kept separate so your data stays in your region.
Frequently asked questions
What is a business logic flaw in simple terms?
It is code that works exactly as written but does something it should not allow. The syntax is valid, there is no injection, and the libraries are patched, yet the application breaks one of its own rules: a cart that accepts a negative quantity, an endpoint that returns another customer's data, an update route with no ownership check. Because the request is well-formed, it looks like normal traffic and slips past scanners and intrusion detection alike.
Why can't SAST or SCA catch business logic vulnerabilities?
Because both tools reason about the code, and a business rule lives outside the code. SAST follows untrusted data to a dangerous sink, which is a syntax-shaped problem. A missing authorization check has no tainted input and no sink, just a guard that was never written, and you cannot pattern-match the absence of a rule the scanner was never given. SCA only compares your dependencies against a CVE database. Neither was built to know your authorization model or your tenant boundary.
Why do AI coding agents produce more business logic flaws?
Because they generate the statistical average of similar code, and the average endpoint on the internet does not enforce your specific rules. Asked to write an update handler, an agent produces one that loads a row and saves it, since that is the common pattern, without the owner check or tenant filter that your domain requires. The output is fluent and looks correct, which makes it pass review, and agents generate far more code per day than anyone reads closely.
What are the most common business logic flaws in AI-generated code?
The recurring ones are broken authorization (a write path with no ownership check), insecure direct object references or IDOR (changing an id in the URL to access someone else's object), missing tenant scoping (a query filtered by id but not by tenant), and quantity or money abuse (negative or zero quantities, float rounding, a price recomputed to zero at checkout). Race conditions on multi-step flows are a fifth class. All of them pass a clean SAST and SCA run.
How do you prevent business logic flaws instead of just detecting them?
You move the check to before the code is written. If the agent knows your rules, use a money type, route writes through an ownership check, scope every query to the tenant, at the moment it generates the handler, it writes the guarded version on the first try and the flaw never exists. A post-hoc scanner can only flag what is already in the diff, which still depends on a human rejecting fluent-looking code. Loading rules into the agent makes the safe pattern the default.
Does this replace my SAST and SCA scanner?
No, it complements them. SAST remains the right tool for injection and taint analysis, and SCA remains the right tool for vulnerable dependencies; both solve syntax-shaped and dependency-shaped problems well. Business logic flaws are an intent-shaped problem that those tools cannot see by design. The complete picture is your existing scanners for syntax and CVEs, plus an agent-time layer that carries your business rules into the moment of generation.
How does VibeDefend know my business rules without reading my code?
It mines the rules that already exist in your repository, the money type you use, the authorization helper your write paths call, the tenant column on your queries, and turns them into governance metadata. Only that metadata is used to steer the agent; the source code itself never crosses the wire, and EU and US tenants are isolated so your data stays in your region. The result is an agent that applies your conventions as defaults before each edit, rather than a scanner inspecting your code after the fact.