Nesta página
- O código gerado por IA é seguro?
- Porque é que tanto código gerado por IA é inseguro?
- Que tipos de vulnerabilidades introduz o código de IA?
- O que falham os scanners, e os próprios modelos?
- Pode confiar-se numa IA para corrigir as suas próprias vulnerabilidades?
- Como é que se torna o código gerado por IA seguro?
- Perguntas frequentes
- O código gerado por IA é seguro?
- É seguro implantar código gerado por IA em produção?
- Porque é que o código gerado por IA é inseguro se o modelo é tão capaz?
- Posso simplesmente pedir à IA que verifique o seu próprio código à procura de vulnerabilidades?
- Quais são as vulnerabilidades mais comuns no código gerado por IA?
- Como é que torno o código gerado por IA seguro?

O código gerado por IA é seguro? Ele corre, passa na demonstração, e parece código que um engenheiro competente escreveu. É precisamente esse o problema. "Funciona" e "seguro" são propriedades diferentes, e um agente de IA otimiza intensamente para a primeira enquanto um prompt de "faz funcionar" nunca pede a segunda. O resultado, medido repetidamente em estudos independentes, é que uma grande parte do código gerado por IA é entregue com vulnerabilidades reais. Este guia dá-lhe a resposta direta, os dados de 2026, as classes de vulnerabilidades que os scanners e até os próprios modelos que escrevem o código falham, e o que é de facto preciso para tornar o código gerado por IA seguro para entrega.
O código gerado por IA é seguro?
Não, não por omissão. O código gerado por IA é tão seguro quanto os controlos à sua volta, e a maioria das configurações de código de IA não tem nenhum controlo que aja antes de o código aterrar. O modelo produz de forma fiável código que compila e passa no caminho feliz; não produz de forma fiável código que resiste a um atacante, porque resistir a um atacante tem que ver com as verificações que estão ausentes, e um prompt que pede uma funcionalidade que funciona nunca pede a guarda em falta.
O enquadramento honesto é que o código gerado por IA não é categoricamente perigoso, é código não revisto produzido a uma velocidade que nenhum humano consegue rever. Um programador júnior também escreve código inseguro, mas devagar o suficiente para que a revisão acompanhe. Um agente de IA escreve milhares de linhas por dia, por isso a lacuna entre "parece certo" e "está certo" alarga-se mais depressa do que qualquer um a consegue fechar. A questão da segurança é, portanto, na verdade uma questão de controlo: o que apanha a vulnerabilidade, e quando.
do código gerado por IA era vulnerável nos cenários de segurança do MITRE Top-25 (NYU, Asleep at the Keyboard)
das soluções de agentes de código de IA eram seguras, face a 61% funcionalmente corretas (Carnegie Mellon SusVibes)
Controlo de Acesso Quebrado, o principal risco no OWASP Top 10, e uma classe que os scanners genéricos raramente apanham
Porque é que tanto código gerado por IA é inseguro?
Porque o modelo reproduz a média dos seus dados de treino, e a média do código público não é segura. Três forças combinam-se, e nenhuma delas é resolvida por um modelo melhor.
Primeiro, o problema do corpus. O modelo aprendeu com um enorme conjunto de código público que está cheio dos clássicos do OWASP: SQL concatenado em strings, verificações de autorização em falta, criptografia fraca, segredos embutidos. Inseguro-por-omissão é o seu prior estatístico, por isso recorre ao padrão comum, e o padrão comum é frequentemente o inseguro.
Segundo, o problema da ausência. A segurança é habitualmente uma guarda que está presente: uma verificação de limites, uma verificação de propriedade, um input com escape. Um modelo a quem se pede um resultado positivo ("adiciona um endpoint de checkout") não adiciona uma guarda negativa que ninguém pediu. A funcionalidade funciona precisamente porque a verificação em falta não afeta o caminho feliz.
Terceiro, o problema do leitor, e é o decisivo. A pessoa que faz o prompt consegue dizer se a funcionalidade funciona. Muitas vezes não consegue dizer se é segura. Essa lacuna, entre a intenção do autor e a capacidade do revisor, é todo o problema de segurança, e é exatamente o que se alarga quando um não especialista faz vibe coding de uma funcionalidade num parágrafo de intenção. Aprofundamos isto em segurança do vibe coding.
Que tipos de vulnerabilidades introduz o código de IA?
As mesmas que os humanos introduzem, reproduzidas mais depressa do que a revisão consegue acompanhar. Estas são as classes que recorrem em todos os estudos e em todas as ferramentas, cada uma ancorada onde a cobrimos em profundidade:
- Injeção (CWE-89, CWE-78). SQL e comandos de shell concatenados a partir de input do utilizador, porque o modelo os aprendeu de um corpus cheio deles. Veja porque é que a maioria das descobertas de SAST é ruído para perceber por que só as alcançáveis importam.
- Autorização quebrada e IDOR (CWE-862, CWE-639). O agente constrói o endpoint que devolve o registo mas raramente a verificação de que quem chama é o seu dono. Este é o risco número um do OWASP e o que os scanners menos veem.
- Segredos embutidos no código (CWE-798). Quando se pede uma integração que funcione, o modelo embute uma chave de API ou palavra-passe para que o código corra à primeira, e ela passa então a viver no repositório e em cada fork.
- Validação de input em falta (CWE-20). Os endpoints gerados confiam nos seus inputs, o que é o facilitador silencioso da injeção e da desserialização a jusante.
- Desserialização insegura (CWE-502). "Carrega o objeto guardado" torna-se
pickleouyaml.loadsobre bytes não confiáveis, transformando um blob armazenado em execução remota de código. - Falhas de lógica de negócio. A classe mais perigosa, porque nenhum scanner está talhado para a apanhar: um carrinho de quantidade negativa, um cupão que se acumula, um reembolso que salta a verificação de propriedade. O código é sintaticamente perfeito e semanticamente errado. Este é o nosso aprofundamento sobre falhas de lógica de negócio no código gerado por IA.
O que falham os scanners, e os próprios modelos?
Dois pontos cegos importam mais, e são a razão pela qual "basta correr um scanner" ou "pedir ao modelo que verifique o seu próprio trabalho" ficam ambos aquém.
O primeiro é a lógica de negócio. Um analisador estático raciocina sobre padrões de código; uma regra de negócio ("só o dono pode editar este documento", "a quantidade tem de ser positiva") vive fora do código, no seu domínio. Não há input contaminado e não há sink perigoso a corresponder, apenas um if que nunca foi escrito, por isso o scanner reporta o ficheiro como limpo enquanto ele é totalmente explorável.
O segundo é o modelo a corrigir os seus próprios trabalhos de casa. Pedir ao mesmo agente que escreveu o código que o reveja herda os mesmos pontos cegos: ele não conhece o seu modelo de autorização, não consegue ver as outras descobertas em redor da linha, e está tão confiante na versão insegura como na segura. Os testes independentes confirmam-no, apenas uma pequena fração das soluções de IA é segura mesmo quando a maioria está funcionalmente correta. Uma verificação fiável precisa de sinal de fora: análise consciente da alcançabilidade que segue o fluxo de dados real, e as suas próprias regras carregadas como verdade de base, não a opinião do próprio modelo.
A questão não é se a IA escreve código inseguro, todos os autores o fazem. É se alguma coisa apanha a linha insegura antes de ela ser entregue, e à velocidade da IA o único sítio que resta para a apanhar é onde a linha é escrita.
Pode confiar-se numa IA para corrigir as suas próprias vulnerabilidades?
Pode confiar-se num agente de IA para aplicar uma correção muito mais do que para decidir o que é uma vulnerabilidade real e alcançável. O modelo é forte a reescrever uma linha assim que sabe precisamente o que mudar; é fraco a julgar se um problema é explorável, que é exatamente o que um scanner maduro já calculou. Por isso o padrão fiável não é "IA, protege o meu código", é "dá ao agente descobertas confirmadas e ordenadas por alcançabilidade mais as tuas regras, deixa-o corrigi-las, e aprova cada diff". Cobrimos esse ciclo em remediação de vulnerabilidades com IA e se um agente pode encontrar e corrigir vulnerabilidades automaticamente.
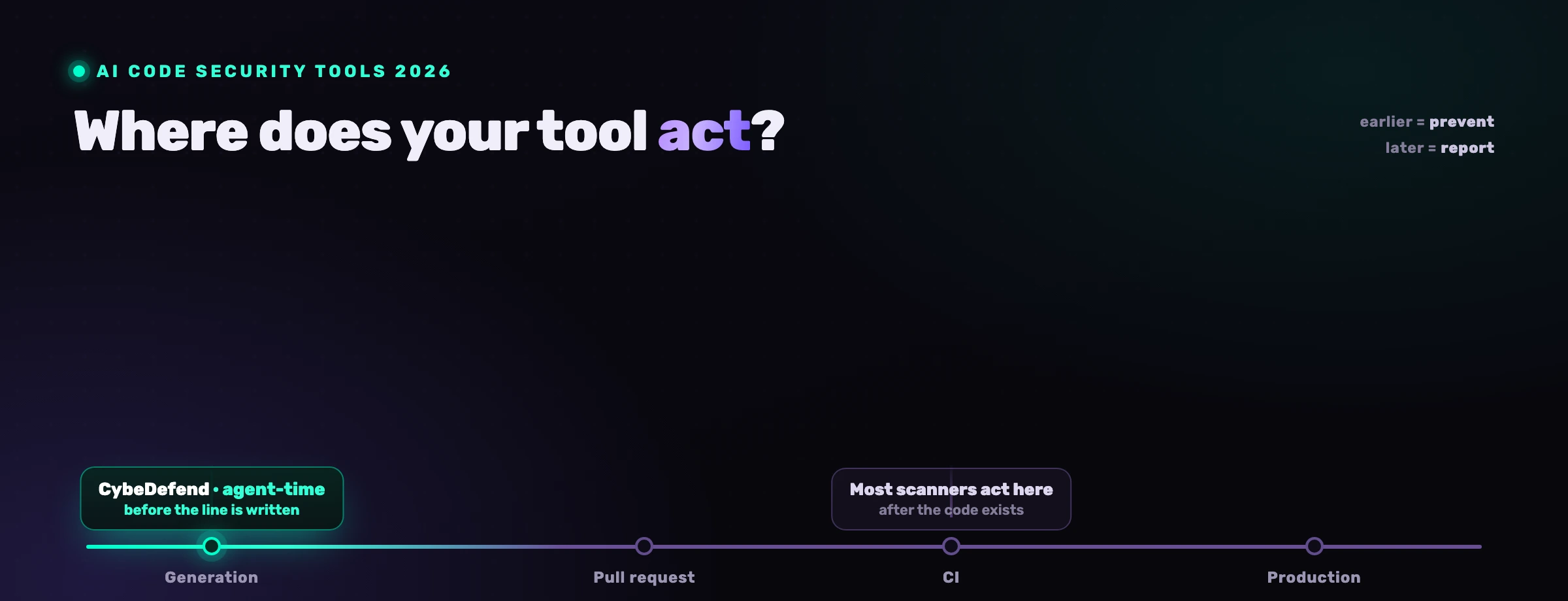
Como é que se torna o código gerado por IA seguro?
Torna-se seguro ao mover o controlo para o momento em que o código é escrito, em vez de confiar no modelo ou esperar por um scanner depois do merge. Três movimentos, por ordem de alavancagem:
- Governar no momento da geração. Carregue as suas regras de segurança e de negócio no agente antes de cada edição, de modo que o padrão seguro seja a omissão para a qual ele recorre. A vulnerabilidade que nunca é escrita não precisa de triagem. Esta é a ideia central de segurança de agentes de código de IA.
- Analisar continuamente e devolver as descobertas ao agente. Mantenha SAST consciente da alcançabilidade, SCA, segredos, IaC e o resto a correr, e coloque as suas descobertas confirmadas nas mãos do agente para que ele remedeie as reais no ciclo.
- Manter o CI e a revisão humana como rede de segurança. Um gate de SAST em cada pull request e um humano a aprovar diffs apanham o que escapa. São necessários, mas à velocidade da IA não podem ser a única linha.
A versão prática completa é como adicionar segurança ao seu fluxo de trabalho de código de IA e como proteger uma aplicação inteira em cinco minutos.
O VibeDefend é a camada que faz os dois primeiros. É uma CLI npm gratuita que instala em segundos e liga o Claude Code, o Cursor, o Windsurf, o OpenAI Codex e o VS Code Copilot a quatro camadas de governação dentro do ciclo do agente.

Três camadas governam o que o agente escreve, Business Rules extraídas do seu repositório, Security Rules de OWASP, SOC 2, RGPD e ISO 27001, e um Action Guard que bloqueia chamadas destrutivas. A quarta, Live Findings, liga o agente à plataforma de AppSec completa da CybeDefend, os seus scanners a correr continuamente com cada descoberta ao vivo no contexto do agente, de modo que o agente não só escreve código mais seguro, como corrige as vulnerabilidades que já tem. Nada do seu código atravessa a rede; apenas metadados de governação estruturados o fazem, em tenants da EU ou dos US mantidos fisicamente separados.
Perguntas frequentes
O código gerado por IA é seguro?
Não por omissão. O código gerado por IA corre de forma fiável e passa no caminho feliz, mas os testes independentes encontram repetidamente uma grande parte dele insegura, cerca de 40% vulnerável no estudo "Asleep at the Keyboard" da NYU, e apenas cerca de 10% das soluções de agentes de código de IA seguras no benchmark SusVibes da Carnegie Mellon, ainda que a maioria estivesse funcionalmente correta. Torna-se seguro quando adiciona um controlo que age onde o código é escrito e mantém a revisão humana e a análise de CI por trás dele.
É seguro implantar código gerado por IA em produção?
Só depois de ser revisto e analisado como qualquer código deve ser, e idealmente depois de ter sido governado enquanto era escrito. Implantar código de IA diretamente a partir de "funciona" é arriscado porque as falhas (autorização em falta, injeção, segredos embutidos, erros de lógica de negócio) não afetam o caminho feliz e por isso sobrevivem a um teste funcional. Controle-o com SAST consciente da alcançabilidade no CI, revisão humana dos caminhos sensíveis à segurança, e um controlo no momento do prompt para que a versão segura seja escrita primeiro.
Porque é que o código gerado por IA é inseguro se o modelo é tão capaz?
Porque a capacidade de produzir código que funciona não é o mesmo que produzir código seguro. O modelo reproduz os padrões inseguros comuns nos seus dados de treino públicos, a segurança é habitualmente uma guarda que tem de ser adicionada em vez de um resultado positivo que um prompt pede, e a pessoa que faz o prompt muitas vezes não consegue avaliar se o resultado é seguro. Nenhum destes é resolvido por um modelo mais inteligente; são resolvidos por um controlo à volta do modelo.
Posso simplesmente pedir à IA que verifique o seu próprio código à procura de vulnerabilidades?
Ajuda um pouco e não é suficiente. O mesmo modelo que escreveu o código partilha os seus pontos cegos: não conhece o seu modelo de autorização nem o limite do tenant, não consegue ver as outras descobertas em redor da linha, e está igualmente confiante nas versões insegura e segura. A verificação fiável precisa de sinal de fora, análise consciente da alcançabilidade e as suas próprias regras como verdade de base, não a autoavaliação do modelo.
Quais são as vulnerabilidades mais comuns no código gerado por IA?
Injeção (CWE-89, CWE-78), autorização quebrada e IDOR (CWE-862, CWE-639), segredos embutidos no código (CWE-798), validação de input em falta (CWE-20), desserialização insegura (CWE-502), e falhas de lógica de negócio. As primeiras cinco são detetáveis por bons scanners quando filtra por alcançabilidade; a última, a lógica de negócio, é a perigosa porque nenhum scanner está talhado para apanhar uma regra sintaticamente perfeita e semanticamente errada.
Como é que torno o código gerado por IA seguro?
Mova o controlo para o momento da geração: carregue as suas regras de segurança e de negócio no agente para que ele escreva o padrão seguro primeiro, analise continuamente e devolva as descobertas confirmadas ao agente para remediar, e mantenha um gate de SAST no CI mais revisão humana como rede de segurança. Confiar que o modelo se autopolicia, ou depender apenas de uma análise pós-merge que chega depois de o agente já ter seguido em frente, é o que deixa a lacuna.