Nesta página
- O que é o vibe coding?
- O vibe coding é seguro?
- Quais são os riscos de segurança do vibe coding?
- Porque é que o vibe coding produz estas falhas?
- Como fazer vibe coding seguro?
- Onde a análise fica aquém: imposição agent-time
- Que ferramentas apanham vulnerabilidades de vibe coding?
- Perguntas frequentes
- O vibe coding é seguro?
- Quais são as vulnerabilidades de vibe coding mais comuns?
- Porque é que o código gerado por IA tem tantas falhas de segurança?
- Um não programador consegue fazer vibe coding com segurança?
- Em que é que o vibe coding difere de usar um autocompletar como o antigo Copilot?
- Um scanner SAST apanha vulnerabilidades de vibe coding?
- Qual é o controlo mais eficaz para vibe coding seguro?
- Por onde começo a proteger um projeto de vibe coding existente?

O vibe coding é a prática de construir software descrevendo o que quer em linguagem simples e deixando um agente de IA escrevê-lo. Você dá o prompt, ele entrega. A funcionalidade funciona, a demo corre bem, o repositório cresce milhares de linhas por semana. O problema não é que o código falhe a correr. O problema é que código que corre e código seguro são coisas diferentes, e a pessoa a dar o prompt geralmente não consegue ler a diferença. Este guia nomeia as classes de risco reais por CWE, mostra código vulnerável e corrigido para cada uma, e explica porque é que a única correção duradoura fica no prompt, antes de a linha insegura ser sequer escrita.
O que é o vibe coding?
O vibe coding é construir software dando prompts a um agente de IA em linguagem natural em vez de escrever o código você mesmo. Descreve o resultado ("adiciona um endpoint de checkout que cobra do cartão guardado"), o agente gera e edita os ficheiros, e itera dando novos prompts. A mudança é que o autor do código é agora o modelo, e o humano é o revisor de uma saída que muitas vezes não consegue ler na totalidade.
O termo espalhou-se no início de 2025 para descrever um fluxo de trabalho em que um programador, ou cada vez mais um não programador, se apoia no agente e aceita o que ele produz desde que o resultado se comporte. Ferramentas como o Claude Code, o Cursor, o Windsurf, o OpenAI Codex e o GitHub Copilot tornaram-no prático: indexam um repositório, editam por toda a árvore, correm comandos e produzem funcionalidades funcionais a partir de um parágrafo de intenção. Isso é genuinamente poderoso. É também onde a lacuna de segurança se abre, porque a velocidade que torna o vibe coding atraente é a mesma velocidade que enterra falhas.
O vibe coding é seguro?
O vibe coding é seguro para as coisas em que o software sempre foi seguro por acidente, e inseguro exatamente nas coisas que exigem um juízo que um prompt não transporta. O agente produz de forma fiável código que compila e passa o caminho feliz. Não produz de forma fiável código que resiste a um atacante, porque a segurança é uma ausência (de uma verificação em falta, de um input não escapado) que um prompt de "faz funcionar" nunca pede.
A resposta honesta é que o vibe coding é tão seguro quanto os controlos à sua volta, e a maioria das configurações de vibe coding não tem nenhum que atue antes de o código aterrar. O modelo aprendeu com um corpus público cheio de padrões inseguros, por isso reproduz-nos à velocidade da máquina. Os testes independentes continuam a aterrar no mesmo sítio: uma grande fatia do código gerado por IA falha testes de segurança mesmo quando está funcionalmente correto, e a lacuna entre "funciona" e "seguro" é onde a falha de segurança vive.
do código gerado por IA era vulnerável em cenários de segurança do MITRE Top-25 (NYU, Asleep at the Keyboard)
das soluções de agentes de código de IA eram seguras, face a 61% funcionalmente corretas (Carnegie Mellon SusVibes)
injeção de prompt, o principal risco LLM pelo 3.º ano consecutivo (OWASP LLM01)
A conclusão não é "não façam vibe coding". É que código com aspeto funcional é precisamente o tipo que um revisor apressado deixa passar, e que mais de 80% das soluções de IA funcionalmente corretas no benchmark SusVibes da Carnegie Mellon ainda carregavam uma vulnerabilidade. Velocidade sem um ponto de controlo de segurança é como se entrega a falha e a funcionalidade no mesmo commit.
Quais são os riscos de segurança do vibe coding?
Os riscos não são novos tipos de vulnerabilidade. São os clássicos do OWASP Top 10, reproduzidos mais depressa do que a revisão consegue acompanhar, porque o modelo escreve o padrão comum e o padrão comum é muitas vezes o inseguro. Aqui estão as classes que recorrem, cada uma ancorada ao seu CWE.
Duas destas merecem um olhar mais atento, porque mostram o quão ordinário é o código gerado. Injeção primeiro. Peça "um endpoint de pesquisa que filtra utilizadores por nome" e o caminho de menor resistência é a concatenação.
# Vulnerable (CWE-89): user input concatenated into SQL
q = f"SELECT * FROM users WHERE name = '{name}'"
db.execute(q)
# Fixed: parameterized query, input never becomes code
db.execute("SELECT * FROM users WHERE name = %s", (name,))
A autorização quebrada é mais subtil, porque a versão vulnerável parece completa. Devolve a forma certa, passa o teste que pede "obter a encomenda 42", e é entregue.
// Vulnerable (CWE-639 IDOR): any logged-in user reads any order
app.get('/orders/:id', auth, async (req, res) => {
const order = await Order.findById(req.params.id)
res.json(order)
})
// Fixed: scope the lookup to the caller who owns it
app.get('/orders/:id', auth, async (req, res) => {
const order = await Order.findOne({ _id: req.params.id, userId: req.user.id })
if (!order) return res.status(404).end()
res.json(order)
})
A diferença entre as duas versões é uma cláusula. Um revisor a ler 5000 linhas por dia não vê a cláusula em falta; vê um endpoint que devolve uma encomenda e segue em frente.
Porque é que o vibe coding produz estas falhas?
Porque o prompt otimiza para o comportamento e o modelo otimiza para o padrão mais comum, e nenhum é o mesmo que segurança. "Faz o checkout funcionar" é uma especificação funcional. Não contém instrução para validar input, delimitar autorização ou parametrizar uma query, por isso o agente preenche a lacuna com o que o seu corpus de treino tornou estatisticamente provável, que é frequentemente a versão insegura.
Há três razões que se agravam. Primeira, o problema do corpus: o modelo aprendeu com código público cheio dos clássicos da OWASP, por isso inseguro-por-omissão é o seu a priori. Segunda, o problema da ausência: a segurança é normalmente uma verificação que está presente, e um modelo a quem se pede um resultado positivo não acrescenta uma proteção negativa que ninguém pediu. Terceira, e a mais decisiva, o problema do leitor.
A pessoa a dar o prompt consegue dizer se a funcionalidade funciona. Geralmente não consegue dizer se é segura. Essa lacuna, entre a intenção do autor e a capacidade do revisor, é o problema de segurança todo.
É por isto que o vibe coding é estruturalmente diferente de um programador júnior a escrever o mesmo código. O júnior é lento o suficiente para a revisão acompanhar, e o revisor está a ler código que um humano escreveu à velocidade humana. O vibe coding remove ambos os travões: a saída chega à velocidade da máquina, e a pessoa responsável por ela muitas vezes não tem a literacia de segurança para a avaliar. O pull request, o lugar onde a AppSec sempre viveu, torna-se um registo de decisões já tomadas em vez de um ponto de controlo.
Como fazer vibe coding seguro?
O vibe coding seguro significa pôr um controlo de segurança onde o código é de facto escrito, que é o prompt, não o pull request. Mantém a velocidade e acrescenta uma camada que molda o que o agente escreve antes de o escrever, mais a habitual validação independente por trás dela. Os princípios abaixo são o que separa "fazemos vibe coding" de "fazemos vibe coding com segurança".
-
Dê as regras ao agente no momento do prompt. O modelo não consegue seguir um standard que nunca vê. Carregue os seus requisitos de segurança (parametrizar queries, delimitar toda a pesquisa a quem chama, nunca incluir um segredo inline) no contexto do agente antes de cada edição, de modo que o padrão seguro seja o valor por omissão a que recorre, não uma reflexão posterior que um scanner assinala mais tarde.
-
Mantenha os segredos totalmente fora de alcance. Sem credenciais em texto simples no workspace que o agente consegue ler. Use um cofre, injete em tempo de execução, e acrescente regras
denypara ficheiros.enve armazéns de credenciais de modo que o agente não possa incluir inline (CWE-798) o que não consegue ver. Rode qualquer coisa que alguma vez apareça num registo. -
Trate cada endpoint gerado como não autorizado até prova em contrário. O hábito de revisão mais valioso para código de vibe coding é verificar que cada caminho que devolve dados se delimita a quem chama. A autorização (CWE-862, CWE-639) é a falha que o agente omite de forma mais fiável e a que nenhum teste apanha.
-
Valide input como um requisito rígido, não um luxo. Exija limites, tipos e allowlists em cada handler gerado. O CWE-20 está a montante da injeção e da desserialização, por isso fechá-lo fecha várias classes de uma só vez.
-
Mantenha um humano no circuito, e um gate de SAST por trás dele. Encaminhe o código gerado através de revisão com escrutínio extra na autenticação, nas queries e na validação, e falhe o build em descobertas de alta severidade. Os testes funcionais passam um endpoint vulnerável mas funcional; só uma verificação consciente da segurança o não faz.
-
Vigie explicitamente as falhas de lógica de negócio. Os scanners não apanham um desconto de quantidade negativa ou um cupão acumulado. Extraia as convenções que o seu próprio código já codifica (o dinheiro é Decimal128, os reembolsos passam por
requireOwner) e imponha-as à medida que o agente escreve. Aprofundamos isto em falhas de lógica de negócio no código gerado por IA.
O padrão transversal às seis é o mesmo: deixe de depender de um controlo que chega depois de o código estar em disco, e mova-o para o momento em que o código é escrito.
Onde a análise fica aquém: imposição agent-time
Percorra de novo as classes de risco e sobressai uma única fraqueza na abordagem padrão. O SAST, os scanners de segredos e a revisão de código atuam todos sobre código que já existe. Concentram-se em torno do pull request, porque é aí que a AppSec sempre viveu. Mas o PR só foi alguma vez um ponto de controlo porque um humano o lia, e à cadência do vibe coding ninguém o lê de ponta a ponta. O scanner torna-se um historiador, a documentar falhas depois de o agente as ter entregado e seguido em frente.
O lugar para impor uma regra é o prompt, antes de a linha insegura ser escrita. Qualquer regra que queira que o agente siga tem de estar nas suas mãos no momento em que escreve, não à espera numa ferramenta que chega quando o código já está em disco.
Leia a coluna da direita como o objetivo. Analisar não está errado; está tarde. A imposição agent-time não substitui o scanner, a revisão ou o gate de CI. Põe um controlo à frente de todos eles, de modo que a linha insegura é reescrita antes de ser sequer sugerida, em vez de apanhada três fases depois por uma ferramenta a ler um diff que ninguém teve tempo de ler.
Que ferramentas apanham vulnerabilidades de vibe coding?
Precisa de dois tipos de controlo, e a maioria das equipas só tem um. O tipo familiar é a deteção: SAST para injeção e criptografia fraca, análise de composição de software para dependências vulneráveis, e análise de segredos para credenciais no histórico. Estes são necessários, e pertencem ao CI em cada pull request. São também reativos, e à velocidade do vibe coding chegam depois de a falha ter sido entregue.
O tipo que falta à maioria das configurações é a prevenção no ponto de autoria: uma camada que vive no ciclo do agente e molda o código à medida que é escrito. É essa a lacuna que o VibeDefend preenche. É uma CLI npm gratuita que instala em cerca de cinco segundos e liga o Claude Code, o Cursor, o Windsurf, o OpenAI Codex e o GitHub Copilot a quatro camadas de governação que correm dentro do ciclo do agente, de modo que a versão segura do código é a primeira versão. Para a imagem completa de como isto se posiciona em cada agente de código de IA, veja o nosso pilar sobre segurança de agentes de código de IA.

As quatro camadas tratam dos modos de falha que este guia nomeou. Regras de Negócio são as convenções extraídas do seu próprio repositório (o dinheiro é Decimal128, a autorização passa por requireOwner), carregadas no agente antes de cada edição de modo que as falhas de lógica de negócio nunca sejam escritas. Regras de Segurança trazem o OWASP Top 10, SOC 2, RGPD e ISO 27001 para dentro do código à medida que é escrito, de modo que a injeção, a validação em falta e a autorização quebrada encontram uma regra na autoria em vez de uma caixa a marcar no momento da auditoria. Action Guard interceta chamadas destrutivas (um sudo rm -rf, uma leitura crua de uma variável de ambiente com forma de segredo, um psql ad-hoc contra um host de produção) antes de dispararem, avisando ou bloqueando conforme a regra, com cada interceção no registo de auditoria. Live Findings liga o agente à plataforma de AppSec completa da CybeDefend, os seus scanners (SAST com alcançabilidade, SCA, segredos, IaC e CI/CD) a correr continuamente, de modo que o agente não só escreve código seguro, como tria e corrige as vulnerabilidades que já tem. Crucialmente, nada do seu código atravessa a rede: as decisões acontecem localmente ao lado do agente, e apenas metadados de governação estruturados (a regra que disparou, o caminho do ficheiro, a severidade, um timestamp) chegam ao backend. Os tenants da EU e dos US são fisicamente separados, e a região é escolhida no momento da instalação, de modo que o controlo está tão perto do código sem se tornar, ele próprio, um risco de exfiltração de dados.
Perguntas frequentes
O vibe coding é seguro?
O vibe coding é seguro para produzir software que funciona e pouco fiável a produzir software seguro, porque um prompt de "faz funcionar" nunca pede a verificação de segurança em falta. Os testes independentes continuam a descobrir que uma grande fatia do código gerado por IA falha testes de segurança mesmo quando está funcionalmente correto. Torna-se seguro de fazer quando acrescenta um controlo que atua no momento da autoria, dá ao agente as suas regras de segurança no seu contexto, mantém um humano no circuito, e protege os pull requests com SAST. Sem isso, o vibe coding entrega o OWASP Top 10 à velocidade da máquina.
Quais são as vulnerabilidades de vibe coding mais comuns?
As classes recorrentes são segredos hardcoded (CWE-798), autorização quebrada e IDOR (CWE-862, CWE-639), injeção (CWE-89 para SQL, CWE-78 para comandos), validação de input em falta (CWE-20), desserialização insegura (CWE-502), e falhas de lógica de negócio. Nenhuma é nova. São os clássicos da OWASP, reproduzidos mais depressa do que a revisão consegue acompanhar, porque o modelo escreve o padrão mais comum e o padrão mais comum é frequentemente o inseguro.
Porque é que o código gerado por IA tem tantas falhas de segurança?
Três razões agravam-se. O modelo aprendeu com um corpus público cheio de padrões inseguros, por isso inseguro-por-omissão é o seu a priori. A segurança é normalmente uma proteção que está presente, e um modelo a quem se pede um resultado positivo não acrescenta uma verificação negativa que ninguém pediu. E a pessoa a dar o prompt consegue dizer se a funcionalidade funciona mas muitas vezes não consegue dizer se é segura, por isso a falha passa a revisão. O resultado é código com aspeto funcional que entrega a vulnerabilidade com a funcionalidade.
Um não programador consegue fazer vibe coding com segurança?
Apenas com um controlo que não dependa de a pessoa ler as implicações de segurança, porque é exatamente essa a competência que um não programador não tem. Um linter ou um scanner que produz descobertas a triar assume que o leitor as consegue interpretar. Uma camada agent-time que carrega as regras no agente e reescreve a linha insegura antes de ela aterrar remove essa dependência: o padrão seguro é o valor por omissão a que o agente recorre, por isso a segurança não assenta na capacidade de quem dá o prompt para detetar uma verificação de autorização em falta.
Em que é que o vibe coding difere de usar um autocompletar como o antigo Copilot?
O antigo autocompletar sugeria um bloco de código que um humano escolhia aceitar; o raio de impacto era um snippet que um programador ainda tinha de colar. O vibe coding deixa o agente tomar ações: edita por toda a árvore, corre comandos e entrega funcionalidades funcionais a partir de um parágrafo de intenção, a um volume que nenhum revisor consegue ler. O modelo de segurança tem de passar de rever um rascunho que um humano aceita para restringir e moldar o que um agente escreve à partida.
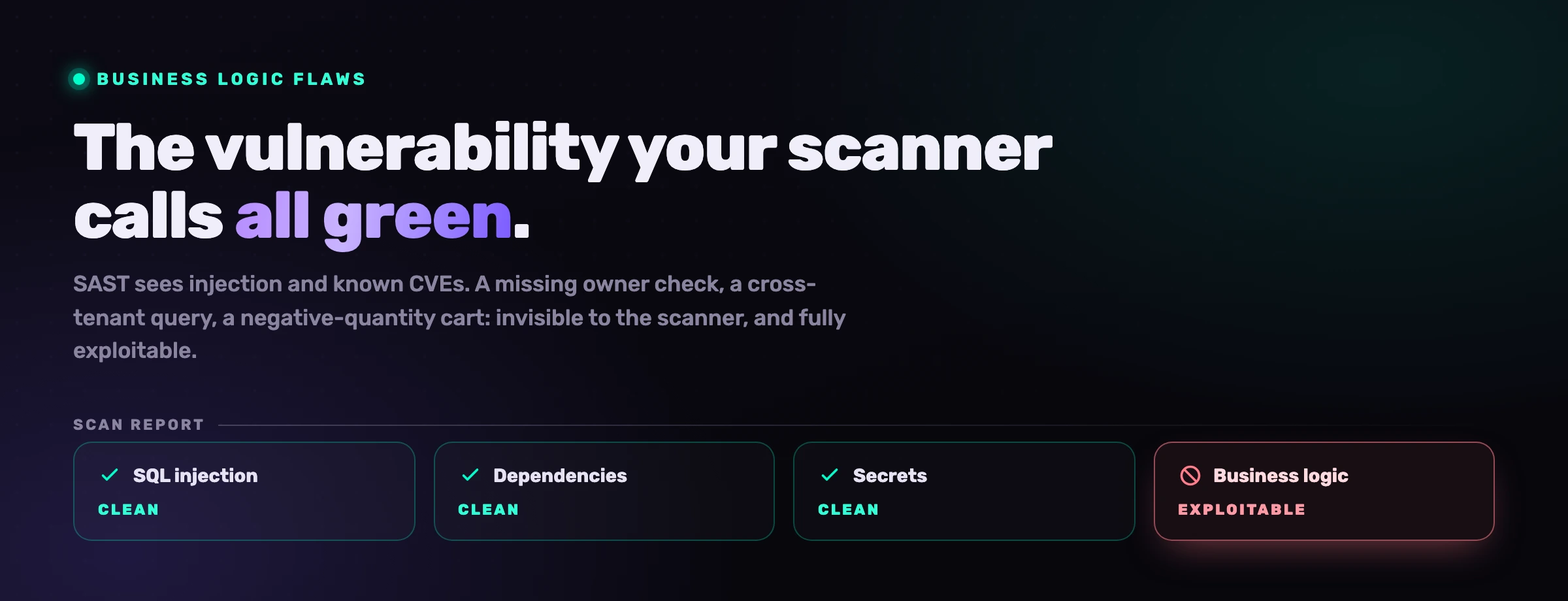
Um scanner SAST apanha vulnerabilidades de vibe coding?
Um scanner SAST apanha uma fatia significativa delas, especialmente injeção e criptografia fraca, e pertence ao CI em cada pull request. O que falha em grande parte são as falhas de lógica de negócio, porque um desconto de quantidade negativa ou um reembolso que salta a verificação de propriedade é sintaticamente perfeito e semanticamente errado, sem assinatura para corresponder. É também reativo: atua depois de o código ser escrito, o que à velocidade do vibe coding significa depois de a falha ter sido entregue. Combine a deteção no CI com a prevenção no momento da autoria.
Qual é o controlo mais eficaz para vibe coding seguro?
Mover o ponto de controlo de segurança do pull request para o prompt. A deteção que corre depois de o código existir está sempre a ler o histórico à cadência do agente, porque ninguém revê milhares de linhas geradas de ponta a ponta. Uma camada que carrega as suas regras de segurança e de negócio no agente antes de cada edição, e reescreve a linha insegura antes de ela aterrar, previne a falha em vez de a encontrar mais tarde. Tudo o resto (SAST, revisão, gates de CI) é defesa em profundidade por trás disso.
Por onde começo a proteger um projeto de vibe coding existente?
Comece por fechar as duas classes que o agente mais omite: analise o histórico à procura de segredos hardcoded e rode qualquer um exposto, depois audite cada endpoint que devolve dados em busca de uma verificação de autorização delimitada a quem chama. Acrescente um gate de SAST ao CI que falha em descobertas de alta severidade, e ponha uma camada agent-time como o VibeDefend à frente para que o código novo seja governado à medida que é escrito. O objetivo é parar de adicionar falhas primeiro, depois reduzir o backlog que os prompts iniciais deixaram para trás.