Nesta página
- O que é uma falha de lógica de negócio?
- Porque é que o SAST não consegue encontrar falhas de lógica de negócio?
- Porque é que os agentes de código de IA produzem mais delas?
- Com que aspeto ficam as falhas de lógica de negócio no código de IA?
- Como apanhar falhas de lógica de negócio no agent-time?
- Em que é que isto difere do SAST e do SCA?
- Perguntas frequentes
- O que é uma falha de lógica de negócio em termos simples?
- Porque é que o SAST ou o SCA não conseguem apanhar vulnerabilidades de lógica de negócio?
- Porque é que os agentes de código de IA produzem mais falhas de lógica de negócio?
- Quais são as falhas de lógica de negócio mais comuns no código gerado por IA?
- Como prevenir falhas de lógica de negócio em vez de apenas detetá-las?
- Isto substitui o meu scanner SAST e SCA?
- Como é que o VibeDefend conhece as minhas regras de negócio sem ler o meu código?
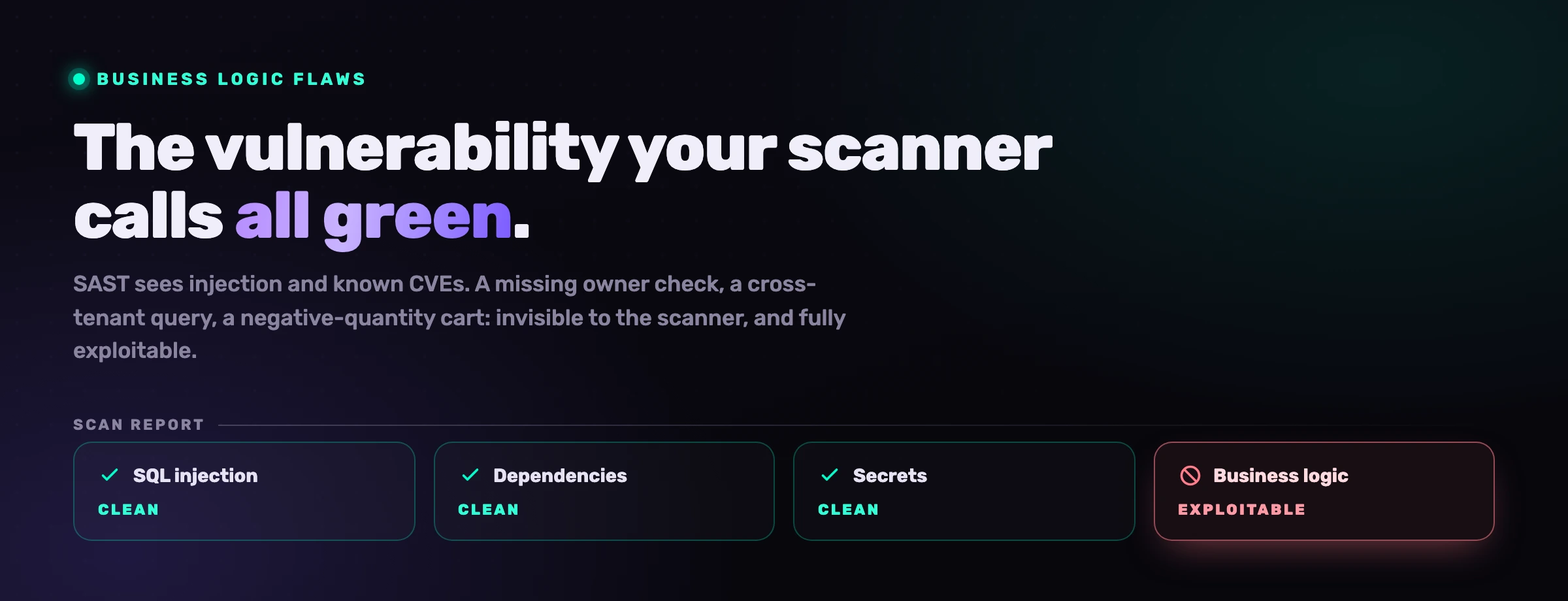
O seu scanner SAST consegue encontrar uma injeção de SQL numa string que nunca viu antes. Não lhe consegue dizer que o seu novo endpoint de checkout deixa um cliente definir uma quantidade negativa e sair com dinheiro. A primeira é um padrão de sintaxe. A segunda é uma regra de negócio, e ao seu scanner nunca lhe disseram quais são as suas regras de negócio. Os agentes de código de IA agravam esta lacuna, porque geram código plausível que faz pattern-matching perfeito com o framework enquanto, em silêncio, quebram a regra que importa.
O que é uma falha de lógica de negócio?
Uma falha de lógica de negócio é uma vulnerabilidade em que o código é sintaticamente correto, livre de injeção e construído sobre bibliotecas com patch, mas viola uma regra que a sua aplicação devia impor. Os exemplos clássicos são autorização quebrada, scoping de tenant em falta, abuso de inteiros ou de quantidade, referências diretas inseguras a objetos (IDOR) e races de ordem de operações. Nada está malformado. A lógica está simplesmente errada sobre o que é permitido.
Esta é a categoria que a OWASP segue como Vulnerabilidades de Lógica de Negócio e, para a fatia de autorização, como Controlo de Acesso Quebrado, o risco número um no OWASP Top 10. Estas falhas são perigosas precisamente porque parecem tráfego normal. Não há payload malformado, não há stack trace, não há assinatura para um sistema de deteção de intrusões corresponder. O pedido está bem formado; simplesmente não devia ter sido honrado. Percorremos um de ponta a ponta no carrinho de 0 EUR: um pipeline CI/CD perfeito, todos os dashboards verdes, e um inventário inteiro adquirido por nada.
Porque é que o SAST não consegue encontrar falhas de lógica de negócio?
Porque o SAST raciocina sobre código, e uma regra de negócio vive fora do código. Um analisador estático consegue seguir dados contaminados de uma fonte até um sink e provar que uma injeção é alcançável. Não tem fonte para o facto de que "só o proprietário de um documento o pode editar" ou "a quantidade tem de ser um inteiro positivo". Essas regras estão na sua cabeça, nos seus tickets e no seu domínio, não em qualquer padrão que o scanner traga.
Este é um limite estrutural, não uma lacuna de maturidade que um scanner mais recente fecha. O SAST sobressai na análise de contaminação (taint): input não confiável, sink perigoso, sem sanitizador pelo meio. Uma verificação de autorização em falta é a forma oposta. Não há input contaminado e não há sink perigoso, apenas uma instrução if que nunca foi escrita. Não se consegue fazer pattern-matching da ausência de uma regra que nunca lhe foi dada. É também por isso que a maioria das equipas se afoga em saída de scanner que falha o risco real, o tema de porque é que a maioria das descobertas de SAST é ruído. O modelo mental certo é um icebergue.
- Injeção: SQL, comando, XSS, SSRF, com um caminho claro de fonte a sink
- CVEs conhecidos em dependências de terceiros (SCA)
- Segredos hardcoded e má configuração óbvia
Abuso de quantidade e de dinheiro
Quantidade negativa ou zero, arredondamento de float, um preço recalculado a zero no checkout.
Autorização quebrada
Uma rota de update ou delete que nunca verifica se quem chama é de facto dono do registo.
IDOR
Trocar um id no URL para ler ou mutar um objeto que pertence a outra pessoa.
Scope de tenant em falta
Uma query filtrada por id mas não por tenant, devolvendo as linhas de outro cliente.
Tudo abaixo da linha de água passa numa execução limpa de SAST e SCA. O código compila, as bibliotecas estão atualizadas, nenhuma injeção é alcançável. O relatório está todo verde, e a aplicação é explorável.
Porque é que os agentes de código de IA produzem mais delas?
Porque um agente de IA é um pattern-matcher treinado na forma do código que funciona, e uma regra de negócio não é uma forma. Quando pede a um agente para "adicionar um endpoint para fazer update a um projeto", ele produz um handler que faz parse do id, carrega a linha e guarda a alteração, porque é isso que milhões de handlers com aspeto correto fazem. Não tem razão para adicionar uma verificação de proprietário ou um filtro de tenant, já que esses são específicos do seu domínio e ausentes do padrão genérico.
Por isso a falha não é um bug que o modelo introduz por acidente; é o resultado previsível de gerar a média de todo o código semelhante. O endpoint de update médio na internet não impõe o seu modelo de autorização. Pior, a saída é fluente e confiante, que é exatamente o que a faz passar a revisão. Um revisor passa os olhos por um handler que parece todos os outros handlers e aprova-o. À velocidade da máquina, os agentes geram agora milhares de linhas por dia, muito mais do que qualquer humano lê de ponta a ponta, por isso a lacuna entre "parece certo" e "está certo" é onde as falhas de segurança se acumulam. Cobrimos a superfície de risco mais ampla no nosso guia sobre segurança de agentes de código de IA.
Um scanner pergunta "é esta linha perigosa?". Uma falha de lógica de negócio responde "não", e é explorada na mesma. A pergunta certa é "este código segue as regras desta base de código?", e nenhuma ferramenta de sintaxe foi alguma vez construída para a responder.
Com que aspeto ficam as falhas de lógica de negócio no código de IA?
Parecem código limpo e idiomático com uma proteção em falta. Aqui estão três classes que um agente entrega rotineiramente. Cada uma compila, cada uma passa o SAST, e cada uma é uma descoberta crítica.
Carrinho de quantidade negativa. Peça um endpoint de "adicionar ao carrinho" e obtém aritmética sem restrição de domínio. Uma quantidade de -1 subtrai ao total.
// Vulnerable: no constraint on quantity
function addToCart(cart, item, quantity) {
cart.total += item.price * quantity; // quantity = -1 lowers the total
return cart;
}
// Fixed: enforce the business rule
function addToCart(cart, item, quantity) {
if (!Number.isInteger(quantity) || quantity < 1) {
throw new ValidationError("quantity must be a positive integer");
}
cart.total += item.price * quantity;
return cart;
}
Autorização em falta / IDOR. Peça uma rota de "update a projeto" e obtém um handler que carrega por id e guarda. Qualquer utilizador autenticado pode passar qualquer id.
# Vulnerable: loads by id, never checks ownership (IDOR)
@app.put("/projects/{project_id}")
def update_project(project_id, body, user):
project = db.get(Project, project_id)
project.name = body.name
db.commit()
return project
# Fixed: require the caller to own the record
@app.put("/projects/{project_id}")
def update_project(project_id, body, user):
project = db.get(Project, project_id)
require_owner(project, user) # 403 if user.id != project.owner_id
project.name = body.name
db.commit()
return project
Scope de tenant em falta. Numa aplicação multi-tenant, uma query filtrada apenas por id vaza entre tenants.
# Vulnerable: filtered by id only, crosses tenant boundary
invoice = db.query(Invoice).filter(Invoice.id == invoice_id).first()
# Fixed: scope every query to the caller's tenant
invoice = db.query(Invoice).filter(
Invoice.id == invoice_id,
Invoice.tenant_id == user.tenant_id,
).first()
Nos três, a diferença entre seguro e explorável é uma linha que codifica uma regra que o agente não tinha forma de conhecer. O caso da quantidade negativa é também, por si só, uma cadeia de exploração completa.
Como apanhar falhas de lógica de negócio no agent-time?
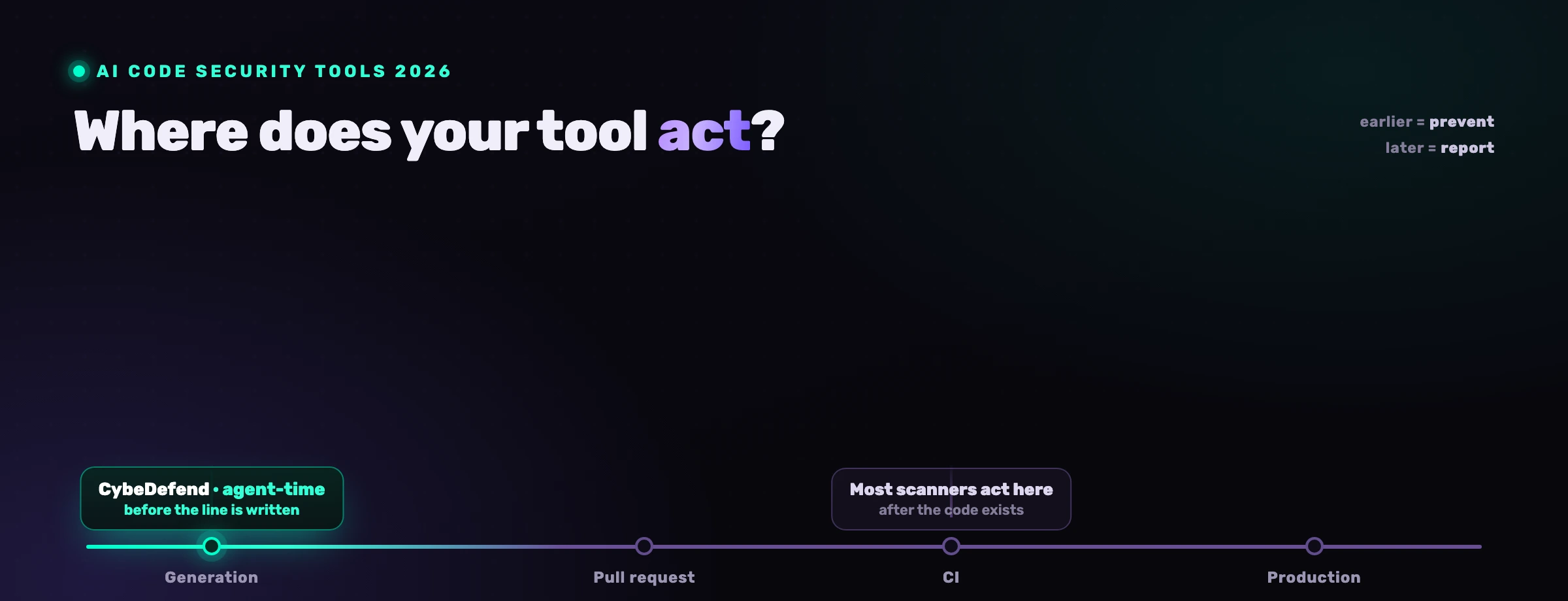
Apanha-as dando ao agente as suas regras antes de ele escrever, não analisando depois de ele entregar. Se o agente sabe "o dinheiro usa Decimal, toda a escrita passa por requireOwner, toda a query é delimitada a tenant_id" no momento em que gera o handler, escreve a versão protegida à primeira tentativa. A falha nunca é criada, por isso não há nada para encontrar, triar ou corrigir mais tarde.
Este é o movimento central: mover a verificação para a esquerda da tecla. Um scanner posterior só consegue assinalar o que já existe no diff, o que significa que um humano ainda tem de ler, compreender e rejeitar código com aspeto fluente sob pressão de tempo. Carregar as regras no contexto do agente transforma a regra num valor por omissão. O agente deixa de produzir o endpoint médio e começa a produzir o seu endpoint. Para domínios onde estas falhas são mais caras, banca e fintech, a imposição no agent-time é a diferença entre uma proteção que existe por conceção e uma que depende de um revisor apanhar a sua ausência.
Em que é que isto difere do SAST e do SCA?
É uma camada diferente do problema. O SAST e o SCA respondem "este código é perigoso ou está desatualizado?". A imposição de regras no agent-time responde "este código segue as regras desta base de código?". Quer ambos: mantenha o SAST para injeção e contaminação, mantenha o SCA para dependências vulneráveis, e acrescente uma camada que transporta as suas regras de negócio para o momento da geração.
A stack legada é necessária e não suficiente. Foi construída para um problema com forma de sintaxe e continua a ser a ferramenta certa para esse problema. As falhas de lógica de negócio são um problema com forma de intenção, e precisam de uma camada que conheça a sua intenção.
O VibeDefend é essa camada. Extrai as regras de negócio já presentes no seu repositório e carrega-as no seu agente de código de IA antes de cada edição, de modo que o agente escreve código que respeita as suas regras de autorização, de dinheiro e de tenant desde a primeira tecla. É uma CLI npm gratuita e instala em cerca de cinco segundos.

A camada de Regras de Negócio é extraída do seu próprio repositório, usar Decimal para dinheiro, encaminhar toda a escrita por requireOwner, delimitar toda a query ao tenant, e é carregada no agente antes de cada edição. Uma quarta camada, Live Findings, liga o agente à plataforma de AppSec completa da CybeDefend, de modo que cada resultado dos seus scanners (SAST com alcançabilidade, SCA, segredos, IaC e CI/CD) está ao vivo no contexto do agente para triar e corrigir, não apenas as regras de lógica de negócio contra as quais escreve. O modelo de privacidade é estrito: nada do seu código atravessa a rede, apenas metadados de governação, e os tenants da EU e dos US são mantidos separados de modo que os seus dados ficam na sua região.
Perguntas frequentes
O que é uma falha de lógica de negócio em termos simples?
É código que funciona exatamente como escrito mas faz algo que não devia permitir. A sintaxe é válida, não há injeção, e as bibliotecas têm patch, mas a aplicação quebra uma das suas próprias regras: um carrinho que aceita uma quantidade negativa, um endpoint que devolve os dados de outro cliente, uma rota de update sem verificação de propriedade. Como o pedido está bem formado, parece tráfego normal e passa despercebido tanto pelos scanners como pela deteção de intrusões.
Porque é que o SAST ou o SCA não conseguem apanhar vulnerabilidades de lógica de negócio?
Porque ambas as ferramentas raciocinam sobre o código, e uma regra de negócio vive fora do código. O SAST segue dados não confiáveis até um sink perigoso, o que é um problema com forma de sintaxe. Uma verificação de autorização em falta não tem input contaminado e não tem sink, apenas uma proteção que nunca foi escrita, e não se consegue fazer pattern-matching da ausência de uma regra que nunca foi dada ao scanner. O SCA só compara as suas dependências contra uma base de dados de CVEs. Nenhum foi construído para conhecer o seu modelo de autorização ou a sua fronteira de tenant.
Porque é que os agentes de código de IA produzem mais falhas de lógica de negócio?
Porque geram a média estatística do código semelhante, e o endpoint médio na internet não impõe as suas regras específicas. Pedido para escrever um handler de update, um agente produz um que carrega uma linha e a guarda, já que esse é o padrão comum, sem a verificação de proprietário ou o filtro de tenant que o seu domínio exige. A saída é fluente e parece correta, o que a faz passar a revisão, e os agentes geram muito mais código por dia do que alguém lê com atenção.
Quais são as falhas de lógica de negócio mais comuns no código gerado por IA?
As recorrentes são autorização quebrada (um caminho de escrita sem verificação de propriedade), referências diretas inseguras a objetos ou IDOR (mudar um id no URL para aceder ao objeto de outra pessoa), scoping de tenant em falta (uma query filtrada por id mas não por tenant), e abuso de quantidade ou de dinheiro (quantidades negativas ou zero, arredondamento de float, um preço recalculado a zero no checkout). As race conditions em fluxos multipasso são uma quinta classe. Todas elas passam numa execução limpa de SAST e SCA.
Como prevenir falhas de lógica de negócio em vez de apenas detetá-las?
Move-se a verificação para antes de o código ser escrito. Se o agente conhece as suas regras, usar um tipo de dinheiro, encaminhar escritas por uma verificação de propriedade, delimitar toda a query ao tenant, no momento em que gera o handler, escreve a versão protegida à primeira tentativa e a falha nunca existe. Um scanner posterior só consegue assinalar o que já está no diff, o que continua a depender de um humano rejeitar código com aspeto fluente. Carregar regras no agente torna o padrão seguro o valor por omissão.
Isto substitui o meu scanner SAST e SCA?
Não, complementa-os. O SAST mantém-se a ferramenta certa para injeção e análise de contaminação, e o SCA mantém-se a ferramenta certa para dependências vulneráveis; ambos resolvem bem problemas com forma de sintaxe e com forma de dependência. As falhas de lógica de negócio são um problema com forma de intenção que essas ferramentas não conseguem ver por conceção. A imagem completa são os seus scanners existentes para sintaxe e CVEs, mais uma camada agent-time que transporta as suas regras de negócio para o momento da geração.
Como é que o VibeDefend conhece as minhas regras de negócio sem ler o meu código?
Extrai as regras que já existem no seu repositório, o tipo de dinheiro que usa, o helper de autorização que os seus caminhos de escrita chamam, a coluna de tenant nas suas queries, e transforma-as em metadados de governação. Apenas esses metadados são usados para orientar o agente; o código-fonte em si nunca atravessa a rede, e os tenants da EU e dos US são isolados de modo que os seus dados ficam na sua região. O resultado é um agente que aplica as suas convenções como valores por omissão antes de cada edição, em vez de um scanner a inspecionar o seu código depois do facto.