In questa pagina
- Il codice generato dall'IA e sicuro?
- Perche cosi tanto codice generato dall'IA e insicuro?
- Che tipi di vulnerabilita introduce il codice IA?
- Cosa sfugge agli scanner, e agli stessi modelli?
- Ci si puo fidare di un'IA per correggere le proprie vulnerabilita?
- Come si rende sicuro il codice generato dall'IA?
- Domande frequenti
- Il codice generato dall'IA e sicuro?
- E sicuro distribuire in produzione codice generato dall'IA?
- Perche il codice generato dall'IA e insicuro se il modello e cosi capace?
- Posso semplicemente chiedere all'IA di controllare il proprio codice per le vulnerabilita?
- Quali sono le vulnerabilita piu comuni nel codice generato dall'IA?
- Come rendo sicuro il codice generato dall'IA?

Il codice generato dall'IA e sicuro? Gira, supera la demo e sembra codice scritto da un ingegnere competente. Ed e proprio questo il problema. "Funziona" e "sicuro" sono proprieta diverse, e un agente IA ottimizza con forza la prima mentre un prompt "fallo funzionare" non chiede mai la seconda. Il risultato, misurato ripetutamente in studi indipendenti, e che una quota rilevante del codice generato dall'IA viene spedito con vulnerabilita reali. Questa guida ti da la risposta diretta, i dati del 2026, le classi di vulnerabilita che sfuggono agli scanner e perfino ai modelli che scrivono il codice, e cosa serve davvero per rendere il codice generato dall'IA sicuro da spedire.
Il codice generato dall'IA e sicuro?
No, non per impostazione predefinita. Il codice generato dall'IA e sicuro quanto i controlli che lo circondano, e la maggior parte delle configurazioni di codifica IA non ha alcun controllo che agisca prima che il codice atterri. Il modello produce in modo affidabile codice che compila e supera il percorso felice; non produce in modo affidabile codice che resista a un attaccante, perche resistere a un attaccante riguarda i controlli che sono assenti, e un prompt che chiede una funzionalita funzionante non chiede mai la guardia mancante.
L'inquadramento onesto e che il codice generato dall'IA non e categoricamente pericoloso, e codice non rivisto prodotto a una velocita che nessun essere umano puo rivedere. Anche uno sviluppatore junior scrive codice insicuro, ma abbastanza lentamente perche la revisione tenga il passo. Un agente IA scrive migliaia di righe al giorno, quindi il divario tra "sembra giusto" e "e giusto" si allarga piu in fretta di quanto chiunque possa colmarlo. La questione della sicurezza e quindi in realta una questione di controllo: cosa coglie la vulnerabilita, e quando.
del codice generato dall'IA era vulnerabile negli scenari di sicurezza MITRE Top-25 (NYU, Asleep at the Keyboard)
delle soluzioni degli agenti di codice IA erano sicure, contro il 61% funzionalmente corretto (Carnegie Mellon SusVibes)
Broken Access Control, il principale rischio nella OWASP Top 10, e una classe che gli scanner generici colgono di rado
Perche cosi tanto codice generato dall'IA e insicuro?
Perche il modello riproduce la media dei suoi dati di addestramento, e la media del codice pubblico non e sicura. Tre forze si sommano, e nessuna di esse si risolve con un modello migliore.
Primo, il problema del corpus. Il modello ha imparato da un'enorme massa di codice pubblico pieno dei classici OWASP: SQL concatenato con stringhe, controlli di autorizzazione mancanti, crittografia debole, segreti inline. L'insicuro-per-default e il suo prior statistico, quindi punta al pattern comune, e il pattern comune e spesso quello insicuro.
Secondo, il problema dell'assenza. La sicurezza e di solito una guardia che e presente: un controllo di limiti, un controllo di proprieta, un input correttamente escapato. Un modello a cui si chiede un esito positivo ("aggiungi un endpoint di checkout") non aggiunge una guardia negativa che nessuno ha richiesto. La funzionalita funziona proprio perche il controllo mancante non incide sul percorso felice.
Terzo, il problema del lettore, ed e quello decisivo. Chi scrive il prompt sa dire se la funzionalita funziona. Spesso non sa dire se e sicura. Quel divario, tra l'intento dell'autore e la capacita del revisore, e l'intero problema della sicurezza, ed e esattamente cio che si allarga quando un non specialista vibe-coda una funzionalita in un paragrafo di intento. Approfondiamo questo tema in sicurezza del vibe coding.
Che tipi di vulnerabilita introduce il codice IA?
Le stesse che introducono gli esseri umani, riprodotte piu in fretta di quanto la revisione riesca a tenere il passo. Queste sono le classi che ricorrono in ogni studio e in ogni strumento, ciascuna ancorata al punto in cui la trattiamo in profondita:
- Injection (CWE-89, CWE-78). SQL e comandi shell concatenati a partire dall'input dell'utente, perche il modello li ha imparati da un corpus che ne e pieno. Vedi perche la maggior parte dei finding SAST e rumore per capire perche contano solo quelle raggiungibili.
- Autorizzazione rotta e IDOR (CWE-862, CWE-639). L'agente costruisce l'endpoint che restituisce il record ma raramente il controllo che il chiamante ne sia il proprietario. E il rischio numero uno di OWASP e quello che gli scanner vedono meno.
- Segreti hardcoded (CWE-798). A cui si chiede un'integrazione funzionante, il modello mette inline una chiave API o una password cosi che il codice giri al primo tentativo, e poi quella vive nel repo e in ogni fork.
- Validazione dell'input mancante (CWE-20). Gli endpoint generati si fidano dei loro input, il che e l'abilitatore silenzioso di injection e deserializzazione a valle.
- Deserializzazione insicura (CWE-502). "Carica l'oggetto salvato" diventa
pickleoyaml.loadsu byte non attendibili, trasformando un blob memorizzato in esecuzione di codice remoto. - Falle di logica di business. La classe piu pericolosa, perche nessuno scanner e fatto per coglierla: un carrello con quantita negativa, un coupon che si cumula, un rimborso che salta il controllo di proprieta. Il codice e sintatticamente perfetto e semanticamente sbagliato. Questo e il nostro approfondimento su falle di logica di business nel codice generato dall'IA.
Cosa sfugge agli scanner, e agli stessi modelli?
Due punti ciechi contano piu di tutti, ed e per questo che "basta eseguire uno scanner" o "chiedi al modello di controllare il proprio lavoro" non bastano entrambi.
Il primo e la logica di business. Un analizzatore statico ragiona su pattern di codice; una regola di business ("solo il proprietario puo modificare questo documento", "la quantita deve essere positiva") vive fuori dal codice, nel tuo dominio. Non c'e input contaminato e nessun sink pericoloso da abbinare, solo un if che non e mai stato scritto, quindi lo scanner segnala il file come pulito mentre e pienamente sfruttabile.
Il secondo e il modello che corregge i propri compiti. Chiedere allo stesso agente che ha scritto il codice di rivederlo eredita gli stessi punti ciechi: non conosce il tuo modello di autorizzazione, non vede gli altri finding intorno alla riga, ed e sicuro della versione insicura quanto di quella sicura. I test indipendenti lo confermano, solo una piccola frazione delle soluzioni IA e sicura anche quando la maggior parte e funzionalmente corretta. Un controllo affidabile ha bisogno di segnale esterno: scansione consapevole della reachability che segue il flusso di dati reale, e le tue regole caricate come verita di base, non l'opinione del modello stesso.
La domanda non e se l'IA scrive codice insicuro, ogni autore lo fa. E se qualcosa coglie la riga insicura prima che venga spedita, e alla velocita dell'IA l'unico posto rimasto per coglierla e dove la riga viene scritta.
Ci si puo fidare di un'IA per correggere le proprie vulnerabilita?
Ci si puo fidare di un agente IA per applicare una correzione molto piu che per decidere cosa sia una vulnerabilita reale e raggiungibile. Il modello e forte nel riscrivere una riga una volta che sa con precisione cosa cambiare; e debole nel giudicare se un problema sia sfruttabile, che e esattamente cio che uno scanner maturo ha gia calcolato. Quindi il pattern affidabile non e "IA, rendi sicuro il mio codice", e "dai all'agente finding confermati e classificati per reachability piu le tue regole, lascia che li corregga, e approva ogni diff". Trattiamo quel loop in AI vulnerability remediation e se un agente possa trovare e correggere le vulnerabilita automaticamente.
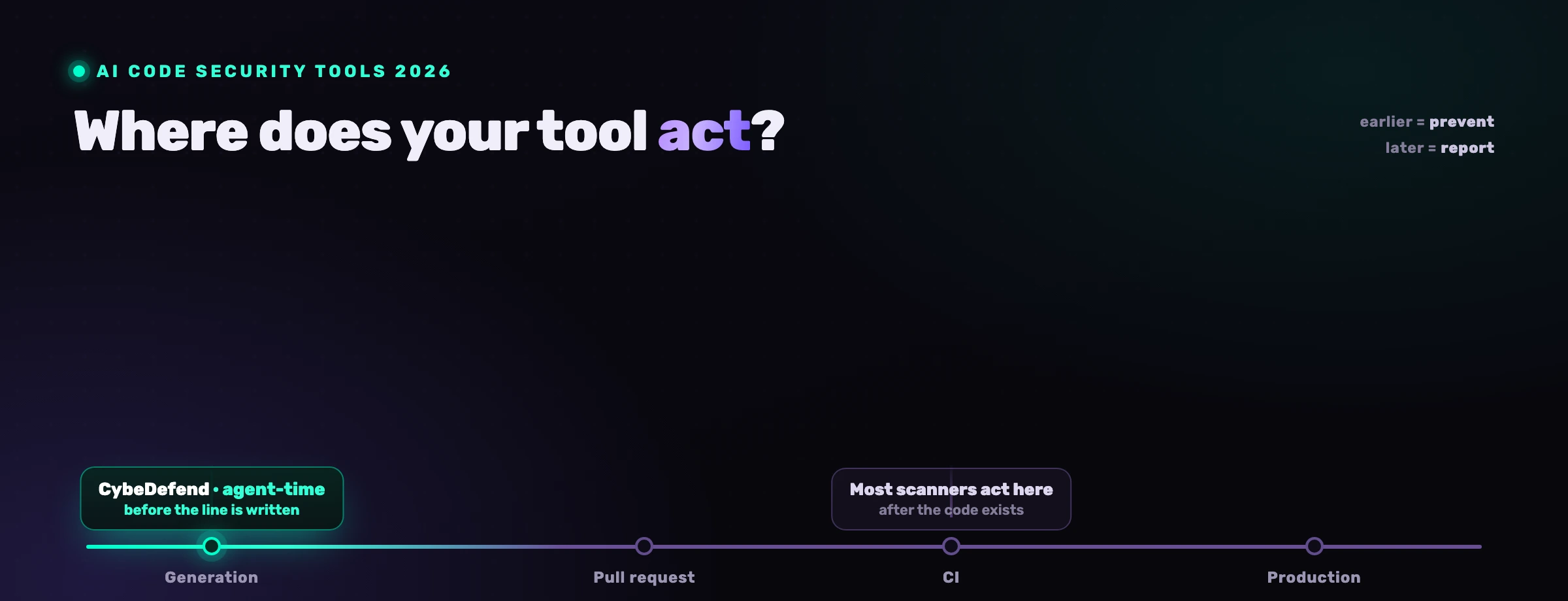
Come si rende sicuro il codice generato dall'IA?
Lo rendi sicuro spostando il controllo al momento in cui il codice viene scritto, anziche confidare nel modello o aspettare uno scanner dopo il merge. Tre mosse, in ordine di leva:
- Governa al momento della generazione. Carica le tue regole di sicurezza e di business nell'agente prima di ogni modifica, cosi che il pattern sicuro sia il default a cui punta. La vulnerabilita che non viene mai scritta non ha bisogno di smistamento. Questa e l'idea centrale di sicurezza degli agenti di codice IA.
- Esegui scansioni in continuo e riporta i finding all'agente. Mantieni in esecuzione SAST consapevole della reachability, SCA, segreti, IaC e il resto, e metti i loro finding confermati nelle mani dell'agente cosi che corregga quelli reali nel loop.
- Mantieni la CI e la revisione umana come rete di sicurezza. Un gate SAST su ogni pull request e un essere umano che approva i diff colgono cio che sfugge. Sono necessari, ma alla velocita dell'IA non possono essere l'unica linea.
La versione pratica completa e come aggiungere sicurezza al tuo workflow di codifica IA e come proteggere un'intera app in cinque minuti.
VibeDefend e il livello che fa le prime due. E una CLI npm gratuita che si installa in pochi secondi e collega Claude Code, Cursor, Windsurf, OpenAI Codex e VS Code Copilot a quattro livelli di governance dentro il loop dell'agente.

Tre livelli governano cio che l'agente scrive, Business Rules estratte dal tuo repo, Security Rules da OWASP, SOC 2, GDPR e ISO 27001, e un Action Guard che blocca le chiamate distruttive. Il quarto, Live Findings, collega l'agente all'intera piattaforma AppSec di CybeDefend, i suoi scanner in esecuzione continua con ogni finding live nel contesto dell'agente, cosi l'agente non si limita a scrivere codice piu sicuro, corregge le vulnerabilita che hai gia. Nulla del tuo codice attraversa la rete; solo metadati di governance strutturati, su tenant EU o US tenuti fisicamente separati.
Domande frequenti
Il codice generato dall'IA e sicuro?
Non per impostazione predefinita. Il codice generato dall'IA gira in modo affidabile e supera il percorso felice, ma i test indipendenti ne rilevano ripetutamente una quota rilevante insicura, circa il 40% vulnerabile nello studio NYU "Asleep at the Keyboard", e solo circa il 10% delle soluzioni degli agenti di codice IA sicure nel benchmark SusVibes di Carnegie Mellon anche se la maggior parte era funzionalmente corretta. Diventa sicuro quando aggiungi un controllo che agisce dove il codice viene scritto e mantieni dietro di esso la revisione umana e la scansione in CI.
E sicuro distribuire in produzione codice generato dall'IA?
Solo dopo che e stato rivisto e scansionato come dovrebbe esserlo qualsiasi codice, e idealmente dopo che e stato governato mentre veniva scritto. Distribuire codice IA direttamente da "funziona" e rischioso perche le falle (autorizzazione mancante, injection, segreti hardcoded, errori di logica di business) non incidono sul percorso felice e quindi sopravvivono a un test funzionale. Mettilo dietro un gate con SAST consapevole della reachability in CI, revisione umana dei percorsi sensibili alla sicurezza e un controllo al momento del prompt cosi che la versione sicura venga scritta per prima.
Perche il codice generato dall'IA e insicuro se il modello e cosi capace?
Perche la capacita di produrre codice funzionante non e la stessa cosa di produrre codice sicuro. Il modello riproduce i pattern insicuri comuni nei suoi dati di addestramento pubblici, la sicurezza e di solito una guardia che va aggiunta anziche un esito positivo che un prompt richiede, e chi scrive il prompt spesso non sa valutare se il risultato sia sicuro. Nessuno di questi si risolve con un modello piu intelligente; si risolvono con un controllo attorno al modello.
Posso semplicemente chiedere all'IA di controllare il proprio codice per le vulnerabilita?
Aiuta un po' e non e sufficiente. Lo stesso modello che ha scritto il codice ne condivide i punti ciechi: non conosce il tuo modello di autorizzazione o il confine di tenant, non vede gli altri finding intorno alla riga, ed e ugualmente sicuro della versione insicura e di quella sicura. Un controllo affidabile ha bisogno di segnale esterno, scansione consapevole della reachability e le tue regole come verita di base, non l'autovalutazione del modello.
Quali sono le vulnerabilita piu comuni nel codice generato dall'IA?
Injection (CWE-89, CWE-78), autorizzazione rotta e IDOR (CWE-862, CWE-639), segreti hardcoded (CWE-798), validazione dell'input mancante (CWE-20), deserializzazione insicura (CWE-502) e falle di logica di business. Le prime cinque sono rilevabili da buoni scanner quando filtri per reachability; l'ultima, la logica di business, e quella pericolosa perche nessuno scanner e fatto per cogliere una regola sintatticamente perfetta e semanticamente sbagliata.
Come rendo sicuro il codice generato dall'IA?
Sposta il controllo al momento della generazione: carica le tue regole di sicurezza e di business nell'agente cosi che scriva per primo il pattern sicuro, esegui scansioni in continuo e riporta i finding confermati all'agente perche li corregga, e mantieni un gate SAST in CI piu la revisione umana come rete di sicurezza. Confidare che il modello faccia la guardia a se stesso, o affidarsi solo a una scansione post-merge che arriva dopo che l'agente e andato avanti, e cio che lascia il divario.