In questa pagina
- Cos'e una falla di logica di business?
- Perche SAST non puo trovare le falle di logica di business?
- Perche gli agenti di codice IA ne producono di piu?
- Che aspetto hanno le falle di logica di business nel codice IA?
- Come si colgono le falle di logica di business agent-time?
- In cosa e diverso da SAST e SCA?
- Domande frequenti
- Cos'e una falla di logica di business in parole semplici?
- Perche SAST o SCA non possono cogliere le vulnerabilita di logica di business?
- Perche gli agenti di codice IA producono piu falle di logica di business?
- Quali sono le falle di logica di business piu comuni nel codice generato dall'IA?
- Come si prevengono le falle di logica di business anziche limitarsi a rilevarle?
- Questo sostituisce il mio scanner SAST e SCA?
- Come fa VibeDefend a conoscere le mie regole di business senza leggere il mio codice?
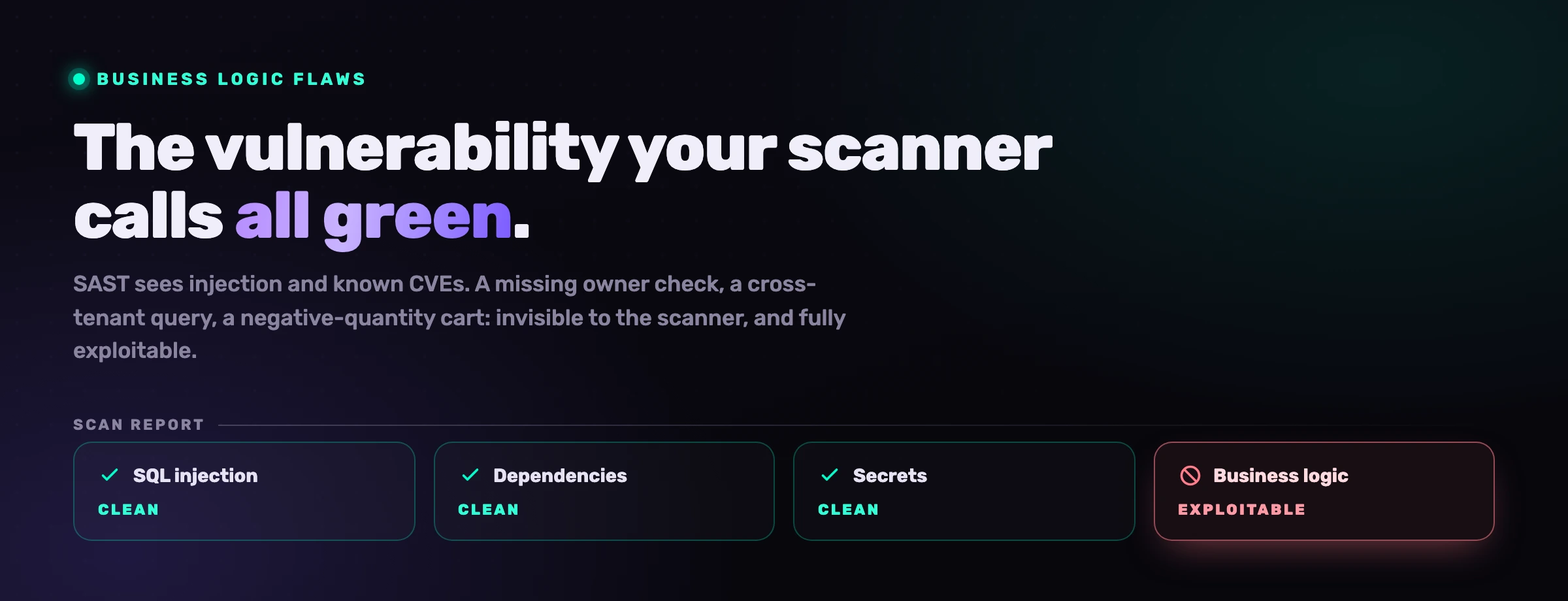
Il tuo scanner SAST puo trovare una SQL injection in una stringa che non ha mai visto prima. Non puo dirti che il tuo nuovo endpoint di checkout permette a un cliente di impostare una quantita negativa e andarsene con i soldi. Il primo e uno schema sintattico. Il secondo e una regola di business, e al tuo scanner non e mai stato detto quali siano le tue regole di business. Gli agenti di codice IA peggiorano questo divario, perche generano codice plausibile che combacia perfettamente con il framework mentre silenziosamente infrange la regola che conta.
Cos'e una falla di logica di business?
Una falla di logica di business e una vulnerabilita in cui il codice e sintatticamente corretto, privo di injection e costruito su librerie aggiornate, eppure viola una regola che la tua applicazione dovrebbe imporre. Gli esempi classici sono autorizzazioni compromesse, scoping per tenant mancante, abuso di interi o quantita, insecure direct object reference (IDOR) e race condition nell'ordine delle operazioni. Nulla e malformato. La logica e semplicemente sbagliata su cio che e consentito.
Questa e la categoria che OWASP traccia come Business Logic Vulnerabilities e, per la fetta dell'autorizzazione, come Broken Access Control, il rischio numero uno nella OWASP Top 10. Queste falle sono pericolose proprio perche sembrano traffico normale. Non c'e payload malformato, nessuno stack trace, nessuna firma che un sistema di rilevamento delle intrusioni possa abbinare. La richiesta e ben formata; semplicemente non sarebbe dovuta essere onorata. Ne abbiamo percorsa una dall'inizio alla fine in il carrello da 0 euro: una pipeline CI/CD perfetta, ogni dashboard verde e un intero inventario portato alla cassa per niente.
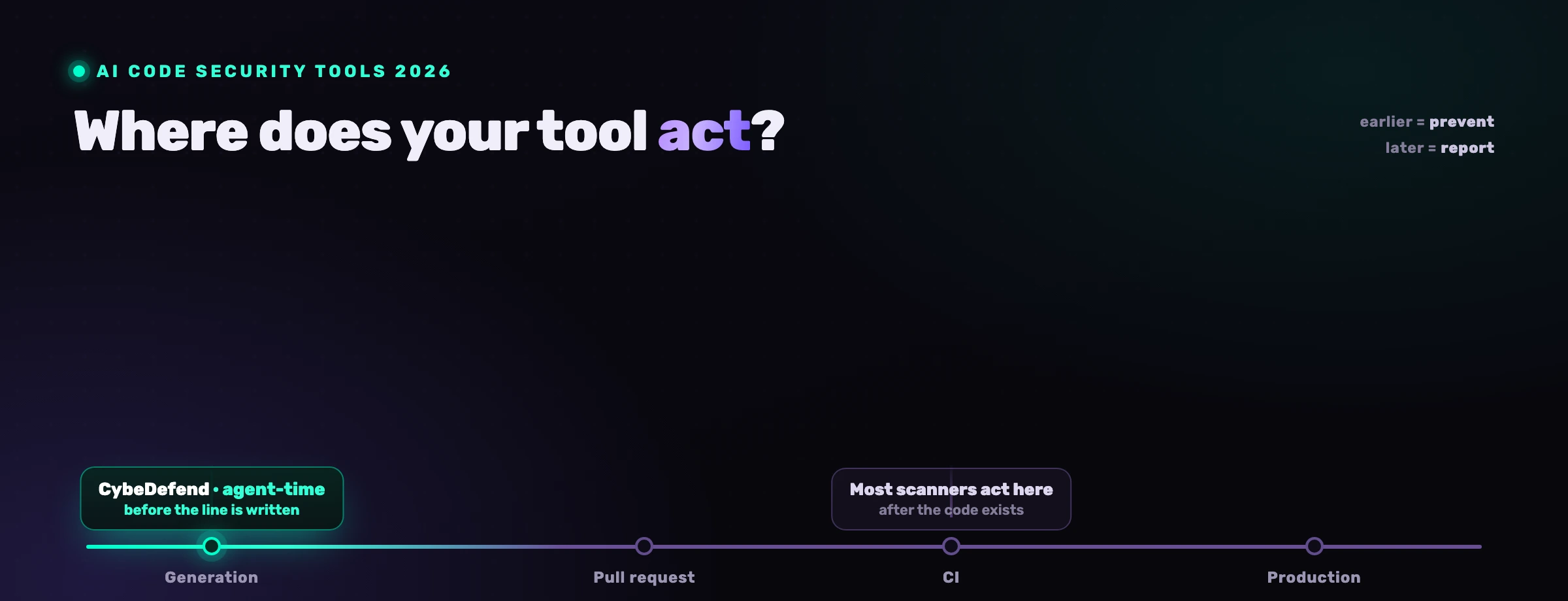
Perche SAST non puo trovare le falle di logica di business?
Perche SAST ragiona sul codice, e una regola di business vive fuori dal codice. Un analizzatore statico puo seguire i dati contaminati da una sorgente a un sink e dimostrare che un'injection e raggiungibile. Non ha alcuna fonte per il fatto che "solo il proprietario di un documento puo modificarlo" o "la quantita deve essere un intero positivo". Quelle regole sono nella tua testa, nei tuoi ticket e nel tuo dominio, non in alcuno schema che lo scanner porta con se.
Questo e un limite strutturale, non un divario di maturita che uno scanner piu recente colma. SAST eccelle nell'analisi della contaminazione: input non attendibile, sink pericoloso, nessun sanitizzatore in mezzo. Un controllo di autorizzazione mancante e la forma opposta. Non c'e input contaminato e non c'e sink pericoloso, solo un'istruzione if che non e mai stata scritta. Non puoi abbinare uno schema all'assenza di una regola che non ti e mai stata data. E anche per questo che la maggior parte dei team annega nell'output dello scanner che si perde il rischio reale, l'argomento di perche la maggior parte dei risultati SAST e rumore. Il modello mentale giusto e un iceberg.
- Injection: SQL, comandi, XSS, SSRF, con un chiaro percorso da sorgente a sink
- CVE noti nelle dipendenze di terze parti (SCA)
- Segreti hardcoded e misconfigurazioni evidenti
Abuso di quantita e denaro
Quantita negativa o zero, arrotondamento dei float, un prezzo ricalcolato a zero alla cassa.
Autorizzazione compromessa
Una route di aggiornamento o cancellazione che non verifica mai che il chiamante possieda davvero il record.
IDOR
Scambiare un id nella URL per leggere o modificare un oggetto che appartiene a qualcun altro.
Scope di tenant mancante
Una query filtrata per id ma non per tenant, che restituisce le righe di un altro cliente.
Tutto cio che sta sotto la linea di galleggiamento supera un'esecuzione pulita di SAST e SCA. Il codice compila, le librerie sono aggiornate, nessuna injection e raggiungibile. Il report e tutto verde, e l'applicazione e sfruttabile.
Perche gli agenti di codice IA ne producono di piu?
Perche un agente IA e un abbinatore di schemi addestrato sulla forma del codice funzionante, e una regola di business non e una forma. Quando chiedi a un agente di "aggiungere un endpoint per aggiornare un progetto", produce un handler che fa il parsing dell'id, carica la riga e salva la modifica, perche e cio che fanno milioni di handler dall'aspetto corretto. Non ha alcun motivo di aggiungere un controllo di proprieta o un filtro di tenant, dato che quelli sono specifici del tuo dominio e assenti dallo schema generico.
Quindi la falla non e un bug che il modello introduce per caso; e il risultato prevedibile di generare la media di tutto il codice simile. L'endpoint di aggiornamento medio su internet non impone il tuo modello di autorizzazione. Peggio ancora, l'output e fluente e sicuro di se, che e esattamente cio che lo fa superare la revisione. Un revisore scorre un handler che sembra ogni altro handler e lo approva. Alla velocita della macchina, gli agenti generano ora migliaia di righe al giorno, molte piu di quante un essere umano ne legga dall'inizio alla fine, quindi il divario tra "sembra giusto" ed "e giusto" e dove le violazioni si accumulano. Copriamo la superficie di rischio piu ampia nella nostra guida alla sicurezza degli agenti di codice IA.
Uno scanner chiede: "questa riga e pericolosa?" Una falla di logica di business risponde "no", e viene sfruttata comunque. La domanda giusta e: "questo codice segue le regole di questo codebase?" e nessuno strumento sintattico e mai stato costruito per rispondere.
Che aspetto hanno le falle di logica di business nel codice IA?
Hanno l'aspetto di codice pulito e idiomatico con un solo guard mancante. Ecco tre classi che un agente spedisce di routine. Ciascuna compila, ciascuna supera SAST, e ciascuna e un risultato critico.
Carrello a quantita negativa. Chiedi un endpoint "aggiungi al carrello" e ottieni aritmetica senza vincolo di dominio. Una quantita di -1 sottrae dal totale.
// Vulnerable: no constraint on quantity
function addToCart(cart, item, quantity) {
cart.total += item.price * quantity; // quantity = -1 lowers the total
return cart;
}
// Fixed: enforce the business rule
function addToCart(cart, item, quantity) {
if (!Number.isInteger(quantity) || quantity < 1) {
throw new ValidationError("quantity must be a positive integer");
}
cart.total += item.price * quantity;
return cart;
}
Autorizzazione mancante / IDOR. Chiedi una route "aggiorna progetto" e ottieni un handler che carica per id e salva. Qualsiasi utente autenticato puo passare qualsiasi id.
# Vulnerable: loads by id, never checks ownership (IDOR)
@app.put("/projects/{project_id}")
def update_project(project_id, body, user):
project = db.get(Project, project_id)
project.name = body.name
db.commit()
return project
# Fixed: require the caller to own the record
@app.put("/projects/{project_id}")
def update_project(project_id, body, user):
project = db.get(Project, project_id)
require_owner(project, user) # 403 if user.id != project.owner_id
project.name = body.name
db.commit()
return project
Scope di tenant mancante. In un'app multi-tenant, una query filtrata solo per id trapela tra i tenant.
# Vulnerable: filtered by id only, crosses tenant boundary
invoice = db.query(Invoice).filter(Invoice.id == invoice_id).first()
# Fixed: scope every query to the caller's tenant
invoice = db.query(Invoice).filter(
Invoice.id == invoice_id,
Invoice.tenant_id == user.tenant_id,
).first()
In tutti e tre, la differenza tra sicuro e sfruttabile e una riga che codifica una regola che l'agente non aveva modo di conoscere. Il caso della quantita negativa e anche di per se una catena di exploit completa.
Come si colgono le falle di logica di business agent-time?
Le cogli dando all'agente le tue regole prima che scriva, non scansionando dopo che ha spedito. Se l'agente sa "il denaro usa Decimal, ogni scrittura passa per requireOwner, ogni query e limitata a tenant_id" nel momento in cui genera l'handler, scrive la versione protetta al primo tentativo. La falla non viene mai creata, quindi non c'e nulla da trovare, smistare o correggere dopo.
Questa e la mossa fondamentale: spostare il controllo a sinistra del tasto premuto. Uno scanner a posteriori puo solo segnalare cio che esiste gia nel diff, il che significa che un essere umano deve comunque leggere, comprendere e rifiutare codice dall'aspetto fluente sotto pressione di tempo. Caricare le regole nel contesto dell'agente trasforma la regola in un'impostazione predefinita. L'agente smette di produrre l'endpoint medio e inizia a produrre il tuo endpoint. Per i domini dove queste falle sono piu costose, banking e fintech, l'imposizione agent-time e la differenza tra un guard che esiste per progettazione e uno che dipende dal fatto che un revisore ne colga l'assenza.
In cosa e diverso da SAST e SCA?
E un livello diverso del problema. SAST e SCA rispondono a "questo codice e pericoloso o obsoleto?" L'imposizione delle regole agent-time risponde a "questo codice segue le regole di questo codebase?" Vuoi entrambi: tieni SAST per injection e contaminazione, tieni SCA per le dipendenze vulnerabili, e aggiungi un livello che porta le tue regole di business nel momento della generazione.
Lo stack legacy e necessario e non sufficiente. E stato costruito per un problema di forma sintattica e resta lo strumento giusto per quel problema. Le falle di logica di business sono un problema di forma di intento, e hanno bisogno di un livello che conosca il tuo intento.
VibeDefend e quel livello. Estrae le regole di business gia presenti nel tuo repository e le carica nel tuo agente di codice IA prima di ogni modifica, cosi l'agente scrive codice che rispetta le tue regole di autorizzazione, denaro e tenant dal primo tasto premuto. E una CLI npm gratuita e si installa in circa cinque secondi.

Il livello delle regole di business viene estratto dal tuo stesso repository, usa Decimal per il denaro, indirizza ogni scrittura attraverso requireOwner, limita ogni query al tenant, e viene caricato nell'agente prima di ogni modifica. Un quarto livello, Live Findings, collega l'agente all'intera piattaforma AppSec di CybeDefend, cosi ogni risultato dei suoi scanner (SAST con reachability, SCA, segreti, IaC e CI/CD) e live nel contesto dell'agente da smistare e correggere, non solo le regole di logica di business rispetto a cui scrive. Il modello di privacy e rigoroso: nulla del tuo codice attraversa la rete, solo metadati di governance, e i tenant EU e US sono tenuti separati cosi che i tuoi dati restino nella tua regione.
Domande frequenti
Cos'e una falla di logica di business in parole semplici?
E codice che funziona esattamente come scritto ma fa qualcosa che non dovrebbe consentire. La sintassi e valida, non c'e injection e le librerie sono aggiornate, eppure l'applicazione infrange una delle sue stesse regole: un carrello che accetta una quantita negativa, un endpoint che restituisce i dati di un altro cliente, una route di aggiornamento senza controllo di proprieta. Poiche la richiesta e ben formata, sembra traffico normale e sfugge sia agli scanner sia al rilevamento delle intrusioni.
Perche SAST o SCA non possono cogliere le vulnerabilita di logica di business?
Perche entrambi gli strumenti ragionano sul codice, e una regola di business vive fuori dal codice. SAST segue i dati non attendibili fino a un sink pericoloso, che e un problema di forma sintattica. Un controllo di autorizzazione mancante non ha input contaminato e non ha sink, solo un guard che non e mai stato scritto, e non puoi abbinare uno schema all'assenza di una regola che allo scanner non e mai stata data. SCA si limita a confrontare le tue dipendenze con un database di CVE. Nessuno dei due e stato costruito per conoscere il tuo modello di autorizzazione o il tuo confine di tenant.
Perche gli agenti di codice IA producono piu falle di logica di business?
Perche generano la media statistica del codice simile, e l'endpoint medio su internet non impone le tue regole specifiche. Chiamato a scrivere un handler di aggiornamento, un agente ne produce uno che carica una riga e la salva, dato che e lo schema comune, senza il controllo di proprieta o il filtro di tenant che il tuo dominio richiede. L'output e fluente e sembra corretto, il che lo fa superare la revisione, e gli agenti generano molto piu codice al giorno di quanto chiunque ne legga attentamente.
Quali sono le falle di logica di business piu comuni nel codice generato dall'IA?
Le ricorrenti sono autorizzazione compromessa (un percorso di scrittura senza controllo di proprieta), insecure direct object reference o IDOR (cambiare un id nella URL per accedere all'oggetto di qualcun altro), scoping per tenant mancante (una query filtrata per id ma non per tenant) e abuso di quantita o denaro (quantita negative o zero, arrotondamento dei float, un prezzo ricalcolato a zero alla cassa). Le race condition sui flussi multi-step sono una quinta classe. Tutte superano un'esecuzione pulita di SAST e SCA.
Come si prevengono le falle di logica di business anziche limitarsi a rilevarle?
Sposti il controllo a prima che il codice venga scritto. Se l'agente conosce le tue regole, usa un tipo per il denaro, indirizza le scritture attraverso un controllo di proprieta, limita ogni query al tenant, nel momento in cui genera l'handler, scrive la versione protetta al primo tentativo e la falla non esiste mai. Uno scanner a posteriori puo solo segnalare cio che e gia nel diff, il che dipende ancora dal fatto che un essere umano rifiuti codice dall'aspetto fluente. Caricare le regole nell'agente rende lo schema sicuro l'impostazione predefinita.
Questo sostituisce il mio scanner SAST e SCA?
No, li completa. SAST resta lo strumento giusto per injection e analisi della contaminazione, e SCA resta lo strumento giusto per le dipendenze vulnerabili; entrambi risolvono bene problemi di forma sintattica e di forma di dipendenza. Le falle di logica di business sono un problema di forma di intento che quegli strumenti non possono vedere per progettazione. Il quadro completo sono i tuoi scanner esistenti per sintassi e CVE, piu un livello agent-time che porta le tue regole di business nel momento della generazione.
Come fa VibeDefend a conoscere le mie regole di business senza leggere il mio codice?
Estrae le regole gia esistenti nel tuo repository, il tipo per il denaro che usi, l'helper di autorizzazione che i tuoi percorsi di scrittura chiamano, la colonna del tenant sulle tue query, e le trasforma in metadati di governance. Solo quei metadati vengono usati per guidare l'agente; il codice sorgente stesso non attraversa mai la rete, e i tenant EU e US sono isolati cosi che i tuoi dati restino nella tua regione. Il risultato e un agente che applica le tue convenzioni come impostazioni predefinite prima di ogni modifica, anziche uno scanner che ispeziona il tuo codice a posteriori.