En esta página
- ¿Es seguro el código generado por IA?
- ¿Por qué tanto código generado por IA es inseguro?
- ¿Qué tipos de vulnerabilidades introduce el código IA?
- ¿Qué no ven los escáneres, y los propios modelos?
- ¿Se puede confiar en una IA para arreglar sus propias vulnerabilidades?
- ¿Cómo logras que el código generado por IA sea seguro?
- Preguntas frecuentes
- ¿Es seguro el código generado por IA?
- ¿Es seguro desplegar código generado por IA en producción?
- ¿Por qué el código generado por IA es inseguro si el modelo es tan capaz?
- ¿Puedo simplemente pedirle a la IA que revise su propio código en busca de vulnerabilidades?
- ¿Cuáles son las vulnerabilidades más comunes en el código generado por IA?
- ¿Cómo logro que el código generado por IA sea seguro?

¿Es seguro el código generado por IA? Funciona, pasa la demo y parece código que escribió un ingeniero competente. Ese es justamente el problema. "Funciona" y "seguro" son propiedades distintas, y un agente de IA optimiza con fuerza la primera mientras un prompt de "haz que funcione" nunca pide la segunda. El resultado, medido una y otra vez en estudios independientes, es que una gran parte del código generado por IA se envía con vulnerabilidades reales. Esta guía te da la respuesta directa, los datos de 2026, las clases de vulnerabilidad que los escáneres e incluso los propios modelos que escriben el código no ven, y lo que realmente hace falta para que el código generado por IA se pueda enviar con seguridad.
¿Es seguro el código generado por IA?
No, no por defecto. El código generado por IA es tan seguro como los controles que lo rodean, y la mayoría de las configuraciones de código IA no tienen ningún control que actúe antes de que el código aterrice. El modelo produce de forma fiable código que compila y pasa el camino feliz; no produce de forma fiable código que resista a un atacante, porque resistir a un atacante tiene que ver con las comprobaciones que están ausentes, y un prompt que pide una funcionalidad que funcione nunca pide la guarda que falta.
El encuadre honesto es que el código generado por IA no es categóricamente peligroso, es código sin revisar producido a una velocidad que ningún humano puede revisar. Un desarrollador junior también escribe código inseguro, pero lo bastante despacio como para que la revisión mantenga el ritmo. Un agente de IA escribe miles de líneas al día, así que la brecha entre "parece correcto" y "es correcto" se ensancha más rápido de lo que nadie puede cerrarla. La pregunta de seguridad es por tanto, en realidad, una pregunta de control: qué atrapa la vulnerabilidad, y cuándo.
del código generado por IA era vulnerable en los escenarios de seguridad MITRE Top-25 (NYU, Asleep at the Keyboard)
de las soluciones de agentes de código IA eran seguras, frente al 61% funcionalmente correctas (Carnegie Mellon SusVibes)
Control de acceso roto, el principal riesgo del OWASP Top 10, y una clase que los escáneres genéricos rara vez detectan
¿Por qué tanto código generado por IA es inseguro?
Porque el modelo reproduce el promedio de sus datos de entrenamiento, y el promedio del código público no es seguro. Tres fuerzas se acumulan, y ninguna se arregla con un modelo mejor.
Primero, el problema del corpus. El modelo aprendió de un enorme cuerpo de código público lleno de los clásicos del OWASP: SQL concatenado con cadenas, comprobaciones de autorización ausentes, criptografía débil, secretos en línea. Inseguro por defecto es su prior estadístico, así que tira del patrón común, y el patrón común suele ser el inseguro.
Segundo, el problema de la ausencia. La seguridad suele ser una guarda que está presente: una comprobación de límites, una comprobación de propiedad, una entrada escapada. Un modelo al que se le pide un resultado positivo ("añade un endpoint de checkout") no añade una guarda negativa que nadie pidió. La funcionalidad funciona precisamente porque la comprobación ausente no afecta al camino feliz.
Tercero, el problema del lector, y es el decisivo. La persona que escribe el prompt puede saber si la funcionalidad funciona. A menudo no puede saber si es segura. Esa brecha, entre la intención del autor y la capacidad del revisor, es el problema de seguridad entero, y es exactamente lo que se ensancha cuando alguien no especialista vibe-codea una funcionalidad en un párrafo de intención. Profundizamos en esto en seguridad del vibe coding.
¿Qué tipos de vulnerabilidades introduce el código IA?
Las mismas que introducen los humanos, reproducidas más rápido de lo que la revisión puede seguir. Estas son las clases que se repiten en cada estudio y cada herramienta, cada una anclada a donde la cubrimos en profundidad:
- Inyección (CWE-89, CWE-78). SQL y comandos de shell concatenados a partir de la entrada del usuario, porque el modelo los aprendió de un corpus lleno de ellos. Mira por qué la mayoría de los hallazgos de SAST son ruido para entender por qué solo importan los alcanzables.
- Autorización rota e IDOR (CWE-862, CWE-639). El agente construye el endpoint que devuelve el registro pero rara vez la comprobación de que quien llama es su dueño. Este es el riesgo número uno del OWASP y el que los escáneres ven menos.
- Secretos embebidos (CWE-798). Cuando se le pide una integración que funcione, el modelo pone en línea una clave de API o una contraseña para que el código corra a la primera, y entonces vive en el repo y en cada fork.
- Validación de entrada ausente (CWE-20). Los endpoints generados confían en sus entradas, que es el habilitador silencioso de la inyección y de la deserialización aguas abajo.
- Deserialización insegura (CWE-502). "Carga el objeto guardado" se convierte en
pickleoyaml.loadsobre bytes no confiables, convirtiendo un blob almacenado en ejecución remota de código. - Fallos de lógica de negocio. La clase más peligrosa, porque ningún escáner está hecho para atraparla: un carrito con cantidad negativa, un cupón que se acumula, un reembolso que se salta la comprobación de propiedad. El código es sintácticamente perfecto y semánticamente erróneo. Este es nuestro análisis a fondo de fallos de lógica de negocio en código generado por IA.
¿Qué no ven los escáneres, y los propios modelos?
Dos puntos ciegos importan más, y son la razón por la que "solo ejecuta un escáner" o "pide al modelo que revise su propio trabajo" se quedan cortos.
El primero es la lógica de negocio. Un analizador estático razona sobre patrones de código; una regla de negocio ("solo el dueño puede editar este documento", "la cantidad debe ser positiva") vive fuera del código, en tu dominio. No hay entrada contaminada ni sink peligroso que casar, solo un if que nunca se escribió, así que el escáner reporta el archivo como limpio cuando es plenamente explotable.
El segundo es el modelo corrigiendo sus propios deberes. Pedirle al mismo agente que escribió el código que lo revise hereda los mismos puntos ciegos: no conoce tu modelo de autorización, no puede ver los demás hallazgos alrededor de la línea, y está tan seguro de la versión insegura como de la segura. Las pruebas independientes lo confirman: solo una pequeña fracción de las soluciones de IA son seguras incluso cuando la mayoría son funcionalmente correctas. Una comprobación fiable necesita señal de fuera: análisis consciente de la alcanzabilidad que sigue el flujo de datos real, y tus propias reglas cargadas como verdad de base, no la opinión del propio modelo.
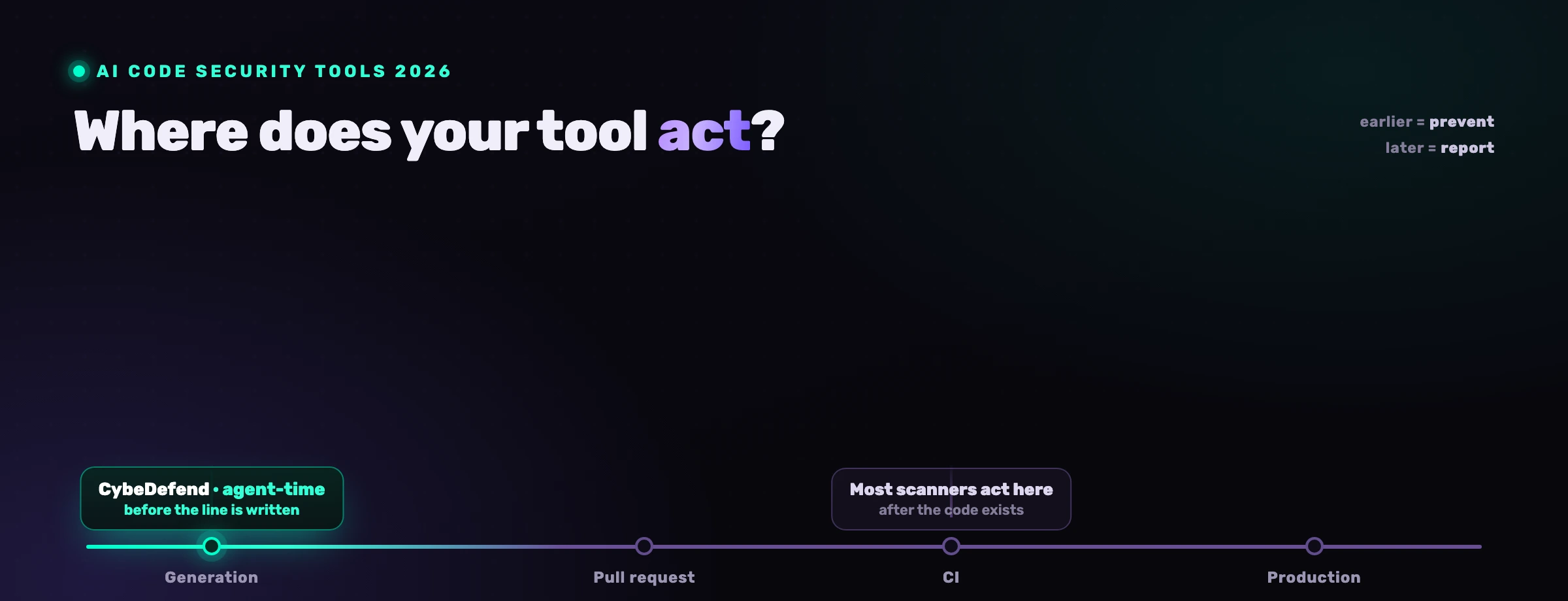
La pregunta no es si la IA escribe código inseguro, todo autor lo hace. Es si algo atrapa la línea insegura antes de enviarse, y a velocidad de IA el único lugar que queda para atraparla es donde se escribe la línea.
¿Se puede confiar en una IA para arreglar sus propias vulnerabilidades?
Puedes confiar en un agente de IA para aplicar un arreglo mucho más que para decidir qué es una vulnerabilidad real y alcanzable. El modelo es fuerte reescribiendo una línea una vez que sabe con precisión qué cambiar; es débil juzgando si un problema es explotable, que es justamente lo que un escáner maduro ya calculó. Así que el patrón fiable no es "IA, asegura mi código", es "dale al agente hallazgos confirmados y clasificados por alcanzabilidad más tus reglas, déjalo arreglarlos y aprueba cada diff". Cubrimos ese bucle en remediación de vulnerabilidades con IA y si un agente puede encontrar y arreglar vulnerabilidades automáticamente.
¿Cómo logras que el código generado por IA sea seguro?
Lo logras moviendo el control al momento en que se escribe el código, en lugar de confiar en el modelo o esperar a un escáner después del merge. Tres movimientos, en orden de apalancamiento:
- Gobierna en tiempo de generación. Carga tus reglas de seguridad y de negocio en el agente antes de cada edición, para que el patrón seguro sea el que toma por defecto. La vulnerabilidad que nunca se escribe no necesita triaje. Esta es la idea central de seguridad de agentes de código IA.
- Escanea de forma continua y devuelve los hallazgos al agente. Mantén corriendo SAST consciente de la alcanzabilidad, SCA, secretos, IaC y lo demás, y pon sus hallazgos confirmados en manos del agente para que remedie los reales dentro del bucle.
- Mantén CI y la revisión humana como red de seguridad. Una puerta de SAST en cada pull request y un humano aprobando diffs atrapan lo que se cuela. Son necesarios, pero a velocidad de IA no pueden ser la única línea.
La versión práctica completa está en cómo añadir seguridad a tu flujo de trabajo de código IA y cómo asegurar una aplicación entera en cinco minutos.
VibeDefend es la capa que hace los dos primeros. Es una CLI de npm gratuita que se instala en segundos y conecta Claude Code, Cursor, Windsurf, OpenAI Codex y VS Code Copilot en cuatro capas de gobierno dentro del bucle del agente.

Tres capas gobiernan lo que el agente escribe: las Business Rules extraídas de tu repo, las Security Rules de OWASP, SOC 2, RGPD e ISO 27001, y un Action Guard que bloquea las llamadas destructivas. La cuarta, Live Findings, conecta el agente con la plataforma completa de AppSec de CybeDefend, sus escáneres corriendo de forma continua con cada hallazgo en vivo en el contexto del agente, así que el agente no solo escribe código más seguro, también arregla las vulnerabilidades que ya tienes. Nada de tu código cruza la red; solo metadatos de gobierno estructurados, en tenants de EU o US mantenidos físicamente separados.
Preguntas frecuentes
¿Es seguro el código generado por IA?
No por defecto. El código generado por IA corre de forma fiable y pasa el camino feliz, pero las pruebas independientes encuentran una y otra vez que una gran parte es insegura, cerca del 40% vulnerable en el estudio "Asleep at the Keyboard" de NYU, y solo alrededor del 10% de las soluciones de agentes de código IA seguras en el benchmark SusVibes de Carnegie Mellon aunque la mayoría fueran funcionalmente correctas. Se vuelve seguro cuando añades un control que actúa donde se escribe el código y mantienes la revisión humana y el escaneo en CI detrás de él.
¿Es seguro desplegar código generado por IA en producción?
Solo después de revisarlo y escanearlo como debería hacerse con cualquier código, e idealmente después de que se gobernara mientras se escribía. Desplegar código IA directo desde "funciona" es arriesgado porque los fallos (autorización ausente, inyección, secretos embebidos, errores de lógica de negocio) no afectan al camino feliz y por eso sobreviven a una prueba funcional. Pon una puerta con SAST consciente de la alcanzabilidad en CI, revisión humana de las rutas sensibles a la seguridad, y un control en tiempo de prompt para que la versión segura se escriba primero.
¿Por qué el código generado por IA es inseguro si el modelo es tan capaz?
Porque la capacidad de producir código que funciona no es lo mismo que producir código seguro. El modelo reproduce los patrones inseguros comunes en sus datos de entrenamiento públicos, la seguridad suele ser una guarda que hay que añadir en lugar de un resultado positivo que un prompt pide, y la persona que escribe el prompt a menudo no puede evaluar si el resultado es seguro. Ninguno de estos se arregla con un modelo más listo; se arreglan con un control alrededor del modelo.
¿Puedo simplemente pedirle a la IA que revise su propio código en busca de vulnerabilidades?
Ayuda un poco y no es suficiente. El mismo modelo que escribió el código comparte sus puntos ciegos: no conoce tu modelo de autorización ni tu frontera de tenant, no puede ver los demás hallazgos alrededor de la línea, y está igual de seguro de la versión insegura que de la segura. Una comprobación fiable necesita señal de fuera, análisis consciente de la alcanzabilidad y tus propias reglas como verdad de base, no la autoevaluación del modelo.
¿Cuáles son las vulnerabilidades más comunes en el código generado por IA?
Inyección (CWE-89, CWE-78), autorización rota e IDOR (CWE-862, CWE-639), secretos embebidos (CWE-798), validación de entrada ausente (CWE-20), deserialización insegura (CWE-502) y fallos de lógica de negocio. Las cinco primeras las detectan buenos escáneres cuando filtras por alcanzabilidad; la última, la lógica de negocio, es la peligrosa porque ningún escáner está hecho para atrapar una regla sintácticamente perfecta y semánticamente errónea.
¿Cómo logro que el código generado por IA sea seguro?
Mueve el control al tiempo de generación: carga tus reglas de seguridad y de negocio en el agente para que escriba el patrón seguro primero, escanea de forma continua y devuelve los hallazgos confirmados al agente para que los remedie, y mantén una puerta de SAST en CI más la revisión humana como red de seguridad. Confiar en que el modelo se autovigile, o depender solo de un escaneo posterior al merge que llega después de que el agente ya siguió adelante, es lo que deja la brecha.