En esta página
- ¿Qué es el vibe coding?
- ¿Es seguro el vibe coding?
- ¿Cuáles son los riesgos de seguridad del vibe coding?
- ¿Por qué el vibe coding produce estos fallos?
- ¿Cómo se hace vibe coding seguro?
- Donde el escaneo se queda corto: aplicación en agent-time
- ¿Qué herramientas atrapan las vulnerabilidades del vibe coding?
- Preguntas frecuentes
- ¿Es seguro el vibe coding?
- ¿Cuáles son las vulnerabilidades más comunes del vibe coding?
- ¿Por qué el código generado por IA tiene tantos fallos de seguridad?
- ¿Puede un no desarrollador hacer vibe coding de forma segura?
- ¿En qué se diferencia el vibe coding de usar un autocompletado como el antiguo Copilot?
- ¿Un escáner SAST atrapa las vulnerabilidades del vibe coding?
- ¿Cuál es el control más eficaz para un vibe coding seguro?
- ¿Por dónde empiezo a asegurar un proyecto de vibe coding existente?

El vibe coding es la práctica de construir software describiendo lo que quieres en lenguaje sencillo y dejando que un agente IA lo escriba. Tú dictas el prompt, él entrega. La funcionalidad funciona, la demo cuaja, el repo crece en miles de líneas a la semana. El problema no es que el código falle al ejecutarse. El problema es que el código que funciona y el código seguro son cosas distintas, y la persona que dicta los prompts normalmente no puede leer la diferencia. Esta guía nombra las clases de riesgo reales por CWE, muestra código vulnerable y corregido para cada una, y explica por qué el único arreglo duradero se sitúa en el prompt, antes de que se escriba siquiera la línea insegura.
¿Qué es el vibe coding?
El vibe coding es construir software dictando prompts a un agente IA en lenguaje natural en lugar de escribir el código tú mismo. Describes el resultado ("añade un endpoint de pago que cobre la tarjeta guardada"), el agente genera y edita los archivos, y tú iteras dictando otro prompt. El cambio es que el autor del código es ahora el modelo, y el humano es el revisor de una salida que a menudo no puede leer del todo.
El término se difundió a principios de 2025 para describir un flujo de trabajo donde un desarrollador, o cada vez más un no desarrollador, se apoya en el agente y acepta lo que produce mientras el resultado se comporte. Herramientas como Claude Code, Cursor, Windsurf, OpenAI Codex y GitHub Copilot lo hicieron práctico: indexan un repositorio, editan por todo el árbol, ejecutan comandos y producen funcionalidades operativas a partir de un párrafo de intención. Eso es genuinamente poderoso. También es donde se abre la brecha de seguridad, porque la velocidad que hace atractivo al vibe coding es la misma velocidad que entierra los fallos.
¿Es seguro el vibe coding?
El vibe coding es seguro para las cosas en las que el software siempre ha sido seguro por accidente, e inseguro exactamente en las cosas que requieren un juicio que un prompt no lleva consigo. El agente produce de forma fiable código que compila y pasa el camino feliz. No produce de forma fiable código que resista a un atacante, porque la seguridad es una ausencia (de una comprobación ausente, de una entrada sin escapar) que un prompt de "haz que funcione" nunca pide.
La respuesta honesta es que el vibe coding es tan seguro como los controles a su alrededor, y la mayoría de los montajes de vibe coding no tienen ninguno que actúe antes de que el código aterrice. El modelo aprendió de un corpus público lleno de patrones inseguros, así que los reproduce a velocidad de máquina. Las pruebas independientes siguen aterrizando en el mismo lugar: una gran parte del código generado por IA no pasa las pruebas de seguridad incluso cuando es funcionalmente correcto, y la brecha entre "funciona" y "es seguro" es donde vive la brecha de seguridad.
del código generado por IA era vulnerable en los escenarios de seguridad del Top-25 de MITRE (NYU, Asleep at the Keyboard)
de las soluciones de agentes de código IA eran seguras, frente al 61% funcionalmente correctas (Carnegie Mellon SusVibes)
inyección de prompts, el principal riesgo LLM por 3.er año consecutivo (OWASP LLM01)
La conclusión no es "no hagas vibe coding". Es que el código de apariencia funcional es precisamente el tipo que un revisor apurado deja pasar, y que más del 80% de las soluciones de IA funcionalmente correctas en el benchmark SusVibes de Carnegie Mellon todavía arrastraban una vulnerabilidad. La velocidad sin un punto de control de seguridad es cómo entregas el fallo y la funcionalidad en el mismo commit.
¿Cuáles son los riesgos de seguridad del vibe coding?
Los riesgos no son tipos de vulnerabilidad nuevos. Son los clásicos del OWASP Top 10, reproducidos más rápido de lo que la revisión puede seguir, porque el modelo escribe el patrón común y el patrón común es a menudo el inseguro. Aquí van las clases que recurren, cada una anclada a su CWE.
Dos de estos merecen una mirada más de cerca, porque muestran lo ordinario que es el código generado. La inyección primero. Pide "un endpoint de búsqueda que filtre usuarios por nombre" y el camino de menor resistencia es la concatenación.
# Vulnerable (CWE-89): user input concatenated into SQL
q = f"SELECT * FROM users WHERE name = '{name}'"
db.execute(q)
# Fixed: parameterized query, input never becomes code
db.execute("SELECT * FROM users WHERE name = %s", (name,))
La autorización rota es más sutil, porque la versión vulnerable parece completa. Devuelve la forma correcta, pasa la prueba que pide "obtener el pedido 42" y se entrega.
// Vulnerable (CWE-639 IDOR): any logged-in user reads any order
app.get('/orders/:id', auth, async (req, res) => {
const order = await Order.findById(req.params.id)
res.json(order)
})
// Fixed: scope the lookup to the caller who owns it
app.get('/orders/:id', auth, async (req, res) => {
const order = await Order.findOne({ _id: req.params.id, userId: req.user.id })
if (!order) return res.status(404).end()
res.json(order)
})
La diferencia entre las dos versiones es una cláusula. Un revisor que lee 5.000 líneas al día no ve la cláusula ausente; ve un endpoint que devuelve un pedido y sigue adelante.
¿Por qué el vibe coding produce estos fallos?
Porque el prompt optimiza para el comportamiento y el modelo optimiza para el patrón más común, y ninguno es lo mismo que la seguridad. "Haz que el pago funcione" es una especificación funcional. No contiene ninguna instrucción para validar la entrada, acotar la autorización o parametrizar una consulta, así que el agente llena el hueco con lo que su corpus de entrenamiento hizo estadísticamente probable, que es con frecuencia la versión insegura.
Hay tres razones que se agravan entre sí. Primera, el problema del corpus: el modelo aprendió de código público lleno de los clásicos de OWASP, así que inseguro-por-defecto es su prior. Segunda, el problema de la ausencia: la seguridad suele ser una comprobación que está presente, y un modelo al que se le pide un resultado positivo no añade una guarda negativa que nadie solicitó. Tercera, y la más decisiva, el problema del lector.
La persona que dicta los prompts puede saber si la funcionalidad funciona. Normalmente no puede saber si es segura. Esa brecha, entre la intención del autor y la capacidad del revisor, es el problema de seguridad entero.
Por eso el vibe coding es estructuralmente distinto de un desarrollador junior que escribe el mismo código. El junior es lo bastante lento como para que la revisión mantenga el ritmo, y el revisor está leyendo código que un humano escribió a velocidad humana. El vibe coding quita ambos frenos: la salida llega a velocidad de máquina, y la persona responsable de ella a menudo carece de la alfabetización en seguridad para evaluarla. El pull request, el lugar donde la AppSec siempre ha vivido, se convierte en una transcripción de decisiones ya tomadas en lugar de un punto de control.
¿Cómo se hace vibe coding seguro?
El vibe coding seguro significa poner un control de seguridad donde el código realmente se escribe, que es el prompt, no el pull request. Mantienes la velocidad y añades una capa que moldea lo que el agente escribe antes de que lo escriba, más la habitual validación independiente por detrás. Los principios de abajo son lo que separa "hacemos vibe coding" de "hacemos vibe coding de forma segura".
-
Dale al agente las reglas en el momento del prompt. El modelo no puede seguir un estándar que nunca ve. Carga tus requisitos de seguridad (parametriza las consultas, acota cada búsqueda a quien llama, nunca incrustes un secreto) en el contexto del agente antes de cada edición, de modo que el patrón seguro sea el valor por defecto al que recurre, no una idea tardía que un escáner marca después.
-
Mantén los secretos completamente fuera de alcance. Sin credenciales en texto plano en el espacio de trabajo que el agente puede leer. Usa una bóveda, inyéctalos en tiempo de ejecución, y añade reglas
denypara los archivos.envy los almacenes de credenciales para que el agente no pueda incrustar (CWE-798) lo que no puede ver. Rota cualquier cosa que aparezca alguna vez en una transcripción. -
Trata cada endpoint generado como no autorizado hasta que se demuestre lo contrario. El hábito de revisión más valioso para el código hecho con vibe coding es comprobar que cada ruta que devuelve datos se acota a quien llama. La autorización (CWE-862, CWE-639) es el fallo que el agente omite con más fiabilidad y el que ninguna prueba atrapa.
-
Valida la entrada como un requisito duro, no como un capricho. Exige límites, tipos y listas de permitidos en cada manejador generado. CWE-20 está aguas arriba de la inyección y la deserialización, así que cerrarlo cierra varias clases a la vez.
-
Mantén a una persona en el bucle, y una puerta SAST por detrás. Encamina el código generado por revisión con escrutinio extra en autenticación, consultas y validación, y falla la compilación ante hallazgos de severidad alta. Las pruebas funcionales pasan un endpoint vulnerable pero funcional; solo una comprobación consciente de la seguridad no lo hace.
-
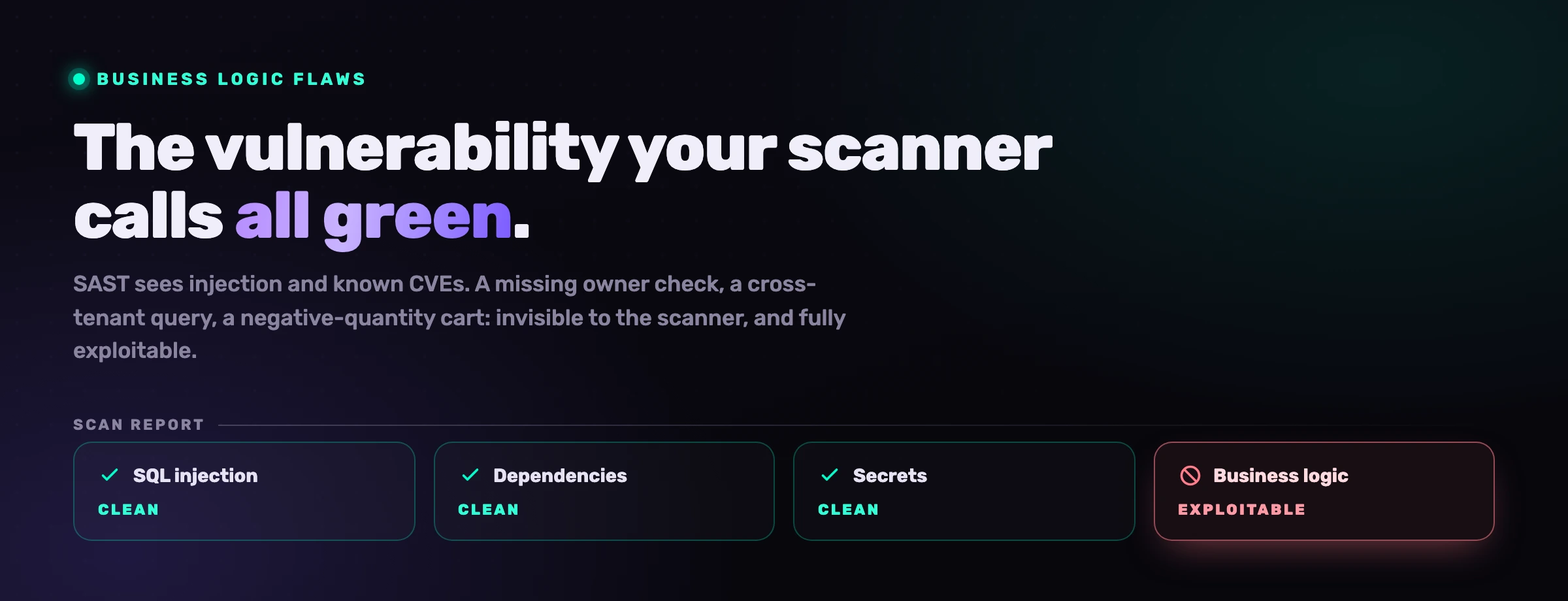
Vigila los fallos de lógica de negocio explícitamente. Los escáneres no atrapan un descuento de cantidad negativa ni un cupón acumulado. Extrae las convenciones que tu propio código ya codifica (el dinero es Decimal128, los reembolsos pasan por
requireOwner) y aplícalas a medida que el agente escribe. Profundizamos en esto en fallos de lógica de negocio en el código generado por IA.
El patrón en las seis es el mismo: deja de apoyarte en un control que llega después de que el código está en disco, y muévelo al momento en que el código se escribe.
Donde el escaneo se queda corto: aplicación en agent-time
Recorre de nuevo las clases de riesgo y destaca una sola debilidad en el enfoque estándar. SAST, los escáneres de secretos y la revisión de código actúan todos sobre código que ya existe. Se agrupan alrededor del pull request, porque ahí ha vivido siempre la AppSec. Pero el PR solo fue un punto de control porque una persona lo leía, y a ritmo de vibe coding ya nadie lo lee de principio a fin. El escáner se convierte en un historiador, documentando fallos después de que el agente los ha entregado y ha pasado a otra cosa.
El lugar para aplicar una regla es el prompt, antes de que se escriba la línea insegura. Cualquier regla que quieras que el agente siga tiene que estar en sus manos en el momento en que escribe, no esperando en una herramienta que llega una vez que el código está en disco.
Lee la columna de la derecha como el objetivo. Escanear no está mal; llega tarde. La aplicación en agent-time no reemplaza al escáner, a la revisión ni a la puerta de CI. Pone un control por delante de todos ellos, de modo que la línea insegura se reescribe antes de siquiera sugerirse, en lugar de atraparse tres etapas después por una herramienta que lee un diff que nadie tuvo tiempo de leer.
¿Qué herramientas atrapan las vulnerabilidades del vibe coding?
Necesitas dos clases de control, y la mayoría de los equipos solo tienen una. La clase conocida es la detección: SAST para la inyección y la criptografía débil, análisis de composición de software para las dependencias vulnerables y escaneo de secretos para las credenciales en el historial. Estas son necesarias, y pertenecen a CI en cada pull request. También son reactivas, y a velocidad de vibe coding llegan después de que el fallo se ha entregado.
La clase que falta en la mayoría de los montajes es la prevención en el punto de autoría: una capa que viva en el bucle del agente y moldee el código a medida que se escribe. Esa es la brecha que llena VibeDefend. Es una CLI de npm gratuita que se instala en unos cinco segundos y conecta Claude Code, Cursor, Windsurf, OpenAI Codex y GitHub Copilot en cuatro capas de gobierno que corren dentro del bucle del agente, de modo que la versión segura del código es la primera versión. Para el cuadro completo de cómo se sitúa esto a través de cada agente de código IA, consulta nuestro pilar sobre seguridad de agentes de código IA.

Las cuatro capas gestionan los modos de fallo que esta guía nombró. Las reglas de negocio son las convenciones extraídas de tu propio repo (el dinero es Decimal128, la autorización pasa por requireOwner), cargadas en el agente antes de cada edición para que los fallos de lógica de negocio nunca se escriban. Las reglas de seguridad llevan OWASP Top 10, SOC 2, RGPD e ISO 27001 al código mientras se escribe, así la inyección, la validación ausente y la autorización rota se topan con una regla en la autoría en lugar de una casilla a marcar en auditoría. El Action Guard intercepta las llamadas destructivas (un sudo rm -rf, una lectura cruda de una variable de entorno con forma de secreto, un psql improvisado contra un host de producción) antes de que se disparen, advirtiendo o bloqueando según la regla, con cada intercepción en el registro de auditoría. Live Findings conecta el agente con la plataforma completa de AppSec de CybeDefend, sus escáneres (SAST con alcanzabilidad, SCA, secretos, IaC y CI/CD) corriendo de forma continua, así que el agente no solo escribe código seguro, también tría y arregla las vulnerabilidades que ya tienes. Es importante destacar que nada de tu código cruza la red: las decisiones ocurren localmente junto al agente, y solo metadatos de gobierno estructurados (la regla que se disparó, la ruta del archivo, la severidad, una marca de tiempo) llegan al backend. Los tenants de EU y US están físicamente separados, y eliges la región en el momento de la instalación, de modo que el control se sitúa tan cerca del código sin convertirse, por sí mismo, en un riesgo de exfiltración de datos.
Preguntas frecuentes
¿Es seguro el vibe coding?
El vibe coding es seguro para producir software que funciona y poco fiable para producir software seguro, porque un prompt de "haz que funcione" nunca pide la comprobación de seguridad ausente. Las pruebas independientes siguen encontrando que una gran parte del código generado por IA no pasa las pruebas de seguridad incluso cuando es funcionalmente correcto. Se vuelve seguro de hacer cuando añades un control que actúa en el momento de la autoría, le das al agente tus reglas de seguridad en su contexto, mantienes a una persona en el bucle y proteges los pull requests con SAST. Sin eso, el vibe coding entrega el OWASP Top 10 a velocidad de máquina.
¿Cuáles son las vulnerabilidades más comunes del vibe coding?
Las clases recurrentes son los secretos codificados (CWE-798), la autorización rota e IDOR (CWE-862, CWE-639), la inyección (CWE-89 para SQL, CWE-78 para comandos), la validación de entrada ausente (CWE-20), la deserialización insegura (CWE-502) y los fallos de lógica de negocio. Ninguna es nueva. Son los clásicos de OWASP, reproducidos más rápido de lo que la revisión puede seguir, porque el modelo escribe el patrón más común y el patrón más común es con frecuencia el inseguro.
¿Por qué el código generado por IA tiene tantos fallos de seguridad?
Tres razones se agravan. El modelo aprendió de un corpus público lleno de patrones inseguros, así que inseguro-por-defecto es su prior. La seguridad suele ser una guarda que está presente, y un modelo al que se le pide un resultado positivo no añade una comprobación negativa que nadie solicitó. Y la persona que dicta los prompts puede saber si la funcionalidad funciona pero a menudo no puede saber si es segura, así que el fallo pasa la revisión. El resultado es código de apariencia funcional que entrega la vulnerabilidad junto con la funcionalidad.
¿Puede un no desarrollador hacer vibe coding de forma segura?
Solo con un control que no dependa de que la persona lea las implicaciones de seguridad, porque esa es exactamente la habilidad que le falta a un no desarrollador. Un linter o un escáner que produce hallazgos a triar da por hecho que el lector puede interpretarlos. Una capa en agent-time que carga las reglas en el agente y reescribe la línea insegura antes de que aterrice elimina esa dependencia: el patrón seguro es el valor por defecto al que recurre el agente, así que la seguridad no descansa en la capacidad de quien dicta el prompt para detectar una comprobación de autorización ausente.
¿En qué se diferencia el vibe coding de usar un autocompletado como el antiguo Copilot?
El antiguo autocompletado sugería un bloque de código que una persona elegía aceptar; el radio de impacto era un fragmento que un desarrollador todavía tenía que pegar. El vibe coding deja que el agente realice acciones: edita por todo el árbol, ejecuta comandos y entrega funcionalidades operativas a partir de un párrafo de intención, a un volumen que ningún revisor puede leer. El modelo de seguridad tiene que pasar de revisar un borrador que una persona acepta a restringir y moldear lo que un agente escribe en primer lugar.
¿Un escáner SAST atrapa las vulnerabilidades del vibe coding?
Un escáner SAST atrapa una parte significativa de ellas, especialmente la inyección y la criptografía débil, y pertenece a CI en cada pull request. Lo que en gran medida pasa por alto son los fallos de lógica de negocio, porque un descuento de cantidad negativa o un reembolso que se salta la comprobación de propiedad es sintácticamente perfecto y semánticamente erróneo, sin firma que emparejar. También es reactivo: actúa después de que el código se escribe, lo que a velocidad de vibe coding significa después de que el fallo se ha entregado. Combina la detección en CI con la prevención en el momento de la autoría.
¿Cuál es el control más eficaz para un vibe coding seguro?
Mover el punto de control de seguridad del pull request al prompt. La detección que corre después de que el código existe siempre está leyendo historia a ritmo de agente, porque nadie revisa miles de líneas generadas de principio a fin. Una capa que carga tus reglas de seguridad y de negocio en el agente antes de cada edición, y reescribe la línea insegura antes de que aterrice, previene el fallo en lugar de encontrarlo después. Todo lo demás (SAST, revisión, puertas de CI) es defensa en profundidad por detrás de eso.
¿Por dónde empiezo a asegurar un proyecto de vibe coding existente?
Empieza cerrando las dos clases que el agente omite más: escanea el historial en busca de secretos codificados y rota cualquier cosa expuesta, luego audita cada endpoint que devuelve datos en busca de una comprobación de autorización acotada a quien llama. Añade una puerta SAST a CI que falle ante hallazgos de severidad alta, y pon una capa en agent-time como VibeDefend por delante para que el código nuevo se gobierne a medida que se escribe. El objetivo es dejar de añadir fallos primero, y luego trabajar a la baja el backlog que dejaron los prompts iniciales.