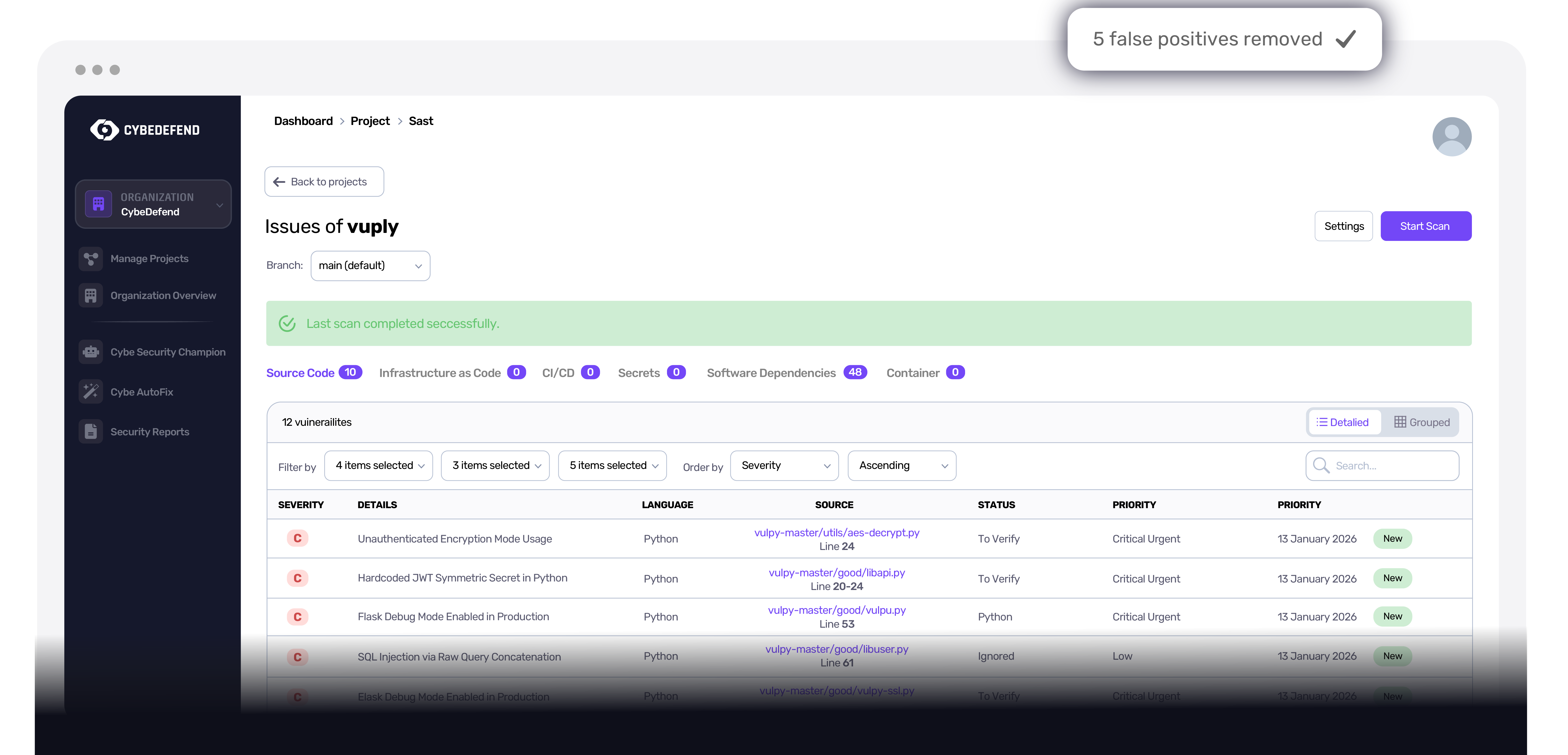
Precisión
Falsos positivos eliminados en origen
Nuestro knowledge graph distingue amenazas reales de falsas alarmas durante el propio escaneo, no después. Hasta 90% menos ruido. Niveles de precisión que las herramientas AST de hace décadas no podían dar.