En esta página
- ¿Qué es un fallo de lógica de negocio?
- ¿Por qué SAST no puede encontrar fallos de lógica de negocio?
- ¿Por qué los agentes de código IA producen más de ellos?
- ¿Qué aspecto tienen los fallos de lógica de negocio en el código IA?
- ¿Cómo atrapas los fallos de lógica de negocio en agent-time?
- ¿En qué se diferencia esto de SAST y SCA?
- Preguntas frecuentes
- ¿Qué es un fallo de lógica de negocio en términos sencillos?
- ¿Por qué SAST o SCA no pueden atrapar las vulnerabilidades de lógica de negocio?
- ¿Por qué los agentes de código IA producen más fallos de lógica de negocio?
- ¿Cuáles son los fallos de lógica de negocio más comunes en el código generado por IA?
- ¿Cómo previenes los fallos de lógica de negocio en lugar de solo detectarlos?
- ¿Esto reemplaza a mi escáner SAST y SCA?
- ¿Cómo conoce VibeDefend mis reglas de negocio sin leer mi código?
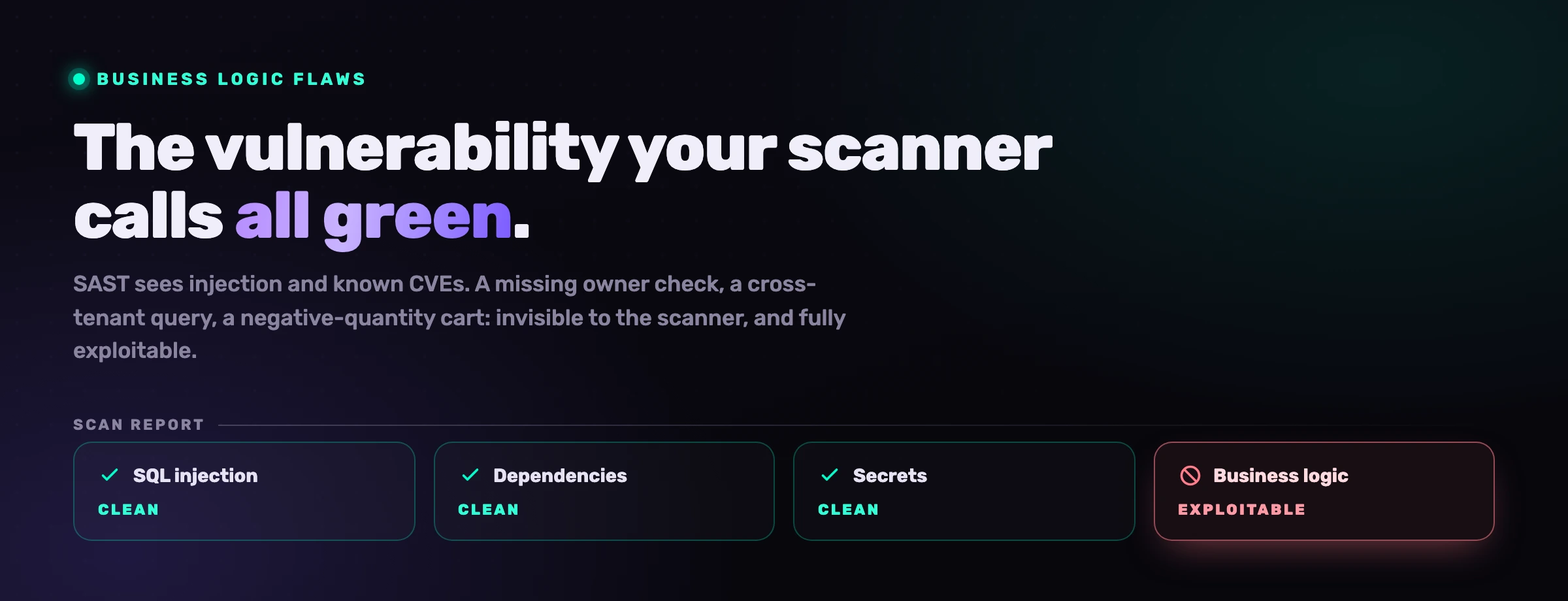
Tu escáner SAST puede encontrar una inyección SQL en una cadena que nunca ha visto antes. No puede decirte que tu nuevo endpoint de pago deja que un cliente fije una cantidad negativa y se marche con dinero. Lo primero es un patrón de sintaxis. Lo segundo es una regla de negocio, y a tu escáner nunca le dijeron cuáles son tus reglas de negocio. Los agentes de código IA empeoran esta brecha, porque generan código plausible que encaja perfectamente con el patrón del framework mientras rompe silenciosamente la regla que importa.
¿Qué es un fallo de lógica de negocio?
Un fallo de lógica de negocio es una vulnerabilidad donde el código es sintácticamente correcto, libre de inyección y construido sobre bibliotecas parcheadas, pero viola una regla que tu aplicación se supone que debe aplicar. Los ejemplos clásicos son la autorización rota, el alcance de tenant ausente, el abuso de enteros o cantidades, las referencias directas inseguras a objetos (IDOR) y las carreras de orden de operaciones. Nada está malformado. La lógica simplemente se equivoca sobre lo que está permitido.
Esta es la categoría que OWASP rastrea como Vulnerabilidades de Lógica de Negocio y, para la parte de autorización, como Control de Acceso Roto, el riesgo número uno en el OWASP Top 10. Estos fallos son peligrosos precisamente porque parecen tráfico normal. No hay carga malformada, ni traza de pila, ni firma que un sistema de detección de intrusiones pueda emparejar. La petición está bien formada; simplemente no debió ser atendida. Recorrimos uno de principio a fin en el carrito de 0 €: un pipeline CI/CD perfecto, todos los paneles en verde y un inventario entero comprado por nada.
¿Por qué SAST no puede encontrar fallos de lógica de negocio?
Porque SAST razona sobre el código, y una regla de negocio vive fuera del código. Un analizador estático puede seguir datos contaminados de una fuente a un sumidero y probar que una inyección es alcanzable. No tiene fuente para el hecho de que "solo el propietario de un documento puede editarlo" o "la cantidad debe ser un entero positivo". Esas reglas están en tu cabeza, en tus tickets y en tu dominio, no en ningún patrón que el escáner trae de fábrica.
Este es un límite estructural, no una brecha de madurez que un escáner más nuevo cierra. SAST destaca en el análisis de contaminación: entrada no confiable, sumidero peligroso, sin saneador en medio. Una comprobación de autorización ausente es la forma opuesta. No hay entrada contaminada ni sumidero peligroso, solo una sentencia if que nunca se escribió. No puedes emparejar por patrón la ausencia de una regla que nunca te dieron. Por eso también la mayoría de los equipos se ahogan en salida de escáner que pasa por alto el riesgo real, el tema de por qué la mayoría de los hallazgos de SAST son ruido. El modelo mental correcto es un iceberg.
- Inyección: SQL, comandos, XSS, SSRF, con una ruta clara de fuente a sumidero
- CVE conocidos en dependencias de terceros (SCA)
- Secretos codificados y configuraciones erróneas obvias
Abuso de cantidad y dinero
Cantidad negativa o cero, redondeo de float, un precio recalculado a cero en el pago.
Autorización rota
Una ruta de actualización o borrado que nunca comprueba que quien llama es realmente el dueño del registro.
IDOR
Cambiar un id en la URL para leer o mutar un objeto que pertenece a otra persona.
Alcance de tenant ausente
Una consulta filtrada por id pero no por tenant, que devuelve las filas de otro cliente.
Todo lo que está bajo la línea de flotación pasa una ejecución limpia de SAST y SCA. El código compila, las bibliotecas están al día, no hay inyección alcanzable. El informe está todo en verde, y la aplicación es explotable.
¿Por qué los agentes de código IA producen más de ellos?
Porque un agente IA es un emparejador de patrones entrenado sobre la forma del código que funciona, y una regla de negocio no es una forma. Cuando le pides a un agente que "añada un endpoint para actualizar un proyecto", produce un manejador que analiza el id, carga la fila y guarda el cambio, porque eso es lo que hacen millones de manejadores de apariencia correcta. No tiene razón alguna para añadir una comprobación de propietario o un filtro de tenant, ya que esos son específicos de tu dominio y están ausentes del patrón genérico.
Así que el fallo no es un error que el modelo introduce por accidente; es el resultado predecible de generar el promedio de todo el código similar. El endpoint de actualización promedio en internet no aplica tu modelo de autorización. Peor aún, la salida es fluida y segura, que es exactamente lo que la hace pasar la revisión. Un revisor ojea un manejador que se parece a todos los demás manejadores y lo aprueba. A velocidad de máquina, los agentes ahora generan miles de líneas al día, muchas más de las que cualquier humano lee de principio a fin, así que la brecha entre "parece correcto" y "es correcto" es donde se acumulan las brechas de seguridad. Cubrimos la superficie de riesgo más amplia en nuestra guía sobre seguridad de agentes de código IA.
Un escáner pregunta "¿es peligrosa esta línea?" Un fallo de lógica de negocio responde "no", y se explota igualmente. La pregunta correcta es "¿sigue este código las reglas de esta base de código?", y ninguna herramienta de sintaxis se construyó jamás para responderla.
¿Qué aspecto tienen los fallos de lógica de negocio en el código IA?
Tienen el aspecto de código limpio e idiomático con una sola guarda ausente. Aquí van tres clases que un agente entrega rutinariamente. Cada una compila, cada una pasa SAST y cada una es un hallazgo crítico.
Carrito de cantidad negativa. Pide un endpoint de "añadir al carrito" y obtienes aritmética sin restricción de dominio. Una cantidad de -1 resta del total.
// Vulnerable: no constraint on quantity
function addToCart(cart, item, quantity) {
cart.total += item.price * quantity; // quantity = -1 lowers the total
return cart;
}
// Fixed: enforce the business rule
function addToCart(cart, item, quantity) {
if (!Number.isInteger(quantity) || quantity < 1) {
throw new ValidationError("quantity must be a positive integer");
}
cart.total += item.price * quantity;
return cart;
}
Autorización ausente / IDOR. Pide una ruta de "actualizar proyecto" y obtienes un manejador que carga por id y guarda. Cualquier usuario autenticado puede pasar cualquier id.
# Vulnerable: loads by id, never checks ownership (IDOR)
@app.put("/projects/{project_id}")
def update_project(project_id, body, user):
project = db.get(Project, project_id)
project.name = body.name
db.commit()
return project
# Fixed: require the caller to own the record
@app.put("/projects/{project_id}")
def update_project(project_id, body, user):
project = db.get(Project, project_id)
require_owner(project, user) # 403 if user.id != project.owner_id
project.name = body.name
db.commit()
return project
Alcance de tenant ausente. En una app multitenant, una consulta filtrada solo por id se filtra entre tenants.
# Vulnerable: filtered by id only, crosses tenant boundary
invoice = db.query(Invoice).filter(Invoice.id == invoice_id).first()
# Fixed: scope every query to the caller's tenant
invoice = db.query(Invoice).filter(
Invoice.id == invoice_id,
Invoice.tenant_id == user.tenant_id,
).first()
En las tres, la diferencia entre seguro y explotable es una línea que codifica una regla que el agente no tenía forma de conocer. El caso de la cantidad negativa es también una cadena de explotación completa por sí solo.
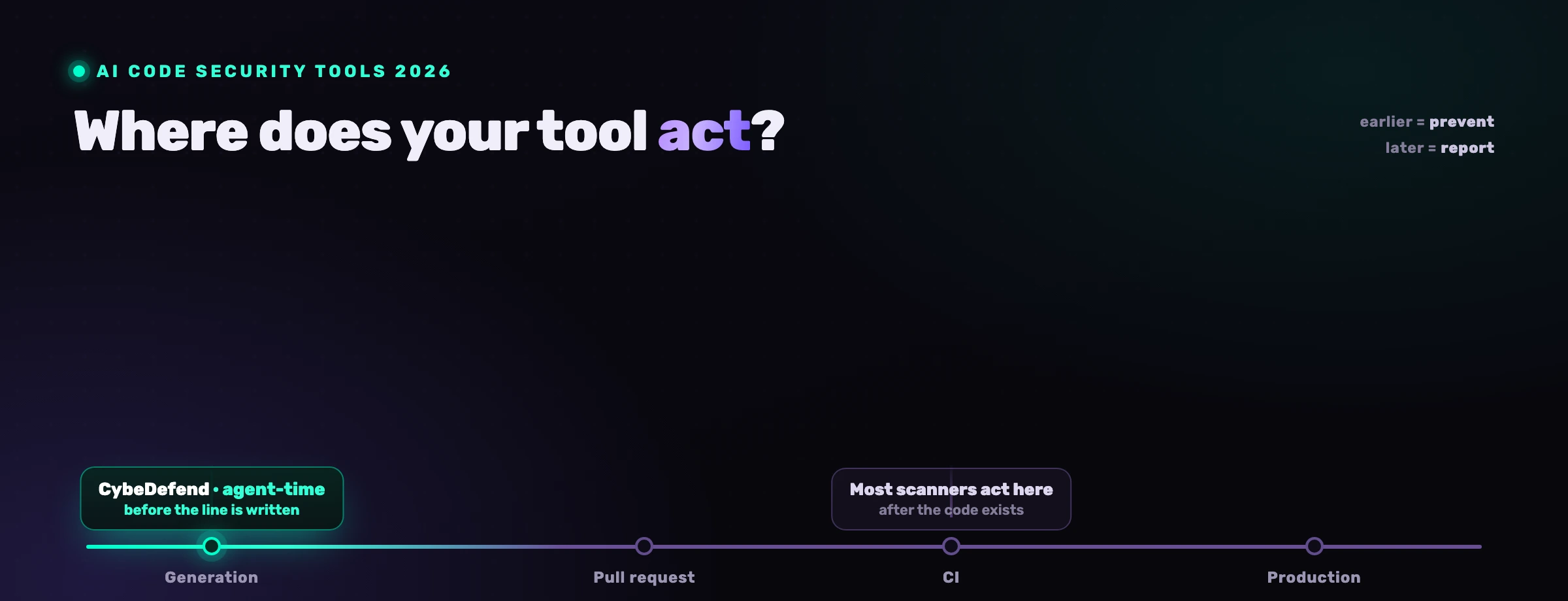
¿Cómo atrapas los fallos de lógica de negocio en agent-time?
Los atrapas dándole al agente tus reglas antes de que escriba, no escaneando después de que entregue. Si el agente sabe "el dinero usa Decimal, cada escritura pasa por requireOwner, cada consulta se acota a tenant_id" en el momento en que genera el manejador, escribe la versión protegida al primer intento. El fallo nunca se crea, así que no hay nada que encontrar, triar o arreglar después.
Este es el movimiento central: desplazar la comprobación a la izquierda de la pulsación de tecla. Un escáner a posteriori solo puede marcar lo que ya existe en el diff, lo que significa que una persona todavía tiene que leer, entender y rechazar código de apariencia fluida bajo presión de tiempo. Cargar las reglas en el contexto del agente convierte la regla en un valor por defecto. El agente deja de producir el endpoint promedio y empieza a producir tu endpoint. Para los dominios donde estos fallos son más caros, banca y fintech, la aplicación en agent-time es la diferencia entre una guarda que existe por diseño y una que depende de que un revisor atrape su ausencia.
¿En qué se diferencia esto de SAST y SCA?
Es una capa distinta del problema. SAST y SCA responden "¿es este código peligroso o está desactualizado?" La aplicación de reglas en agent-time responde "¿sigue este código las reglas de esta base de código?" Quieres ambas: conserva SAST para la inyección y la contaminación, conserva SCA para las dependencias vulnerables, y añade una capa que lleve tus reglas de negocio al momento de la generación.
El stack heredado es necesario y no suficiente. Se construyó para un problema con forma de sintaxis y sigue siendo la herramienta correcta para ese problema. Los fallos de lógica de negocio son un problema con forma de intención, y necesitan una capa que conozca tu intención.
VibeDefend es esa capa. Extrae las reglas de negocio ya presentes en tu repositorio y las carga en tu agente de código IA antes de cada edición, de modo que el agente escribe código que respeta tus reglas de autorización, dinero y tenant desde la primera pulsación de tecla. Es una CLI de npm gratuita y se instala en unos cinco segundos.

La capa de reglas de negocio se extrae de tu propio repositorio, usa Decimal para el dinero, encamina cada escritura por requireOwner, acota cada consulta al tenant, y se carga en el agente antes de cada edición. Una cuarta capa, Live Findings, conecta el agente con la plataforma completa de AppSec de CybeDefend, de modo que cada resultado de sus escáneres (SAST con alcanzabilidad, SCA, secretos, IaC y CI/CD) está en vivo en el contexto del agente para triar y arreglar, no solo las reglas de lógica de negocio contra las que escribe. El modelo de privacidad es estricto: nada de tu código cruza la red, solo metadatos de gobierno, y los tenants de EU y US se mantienen separados para que tus datos permanezcan en tu región.
Preguntas frecuentes
¿Qué es un fallo de lógica de negocio en términos sencillos?
Es código que funciona exactamente como está escrito pero hace algo que no debería permitir. La sintaxis es válida, no hay inyección y las bibliotecas están parcheadas, pero la aplicación rompe una de sus propias reglas: un carrito que acepta una cantidad negativa, un endpoint que devuelve los datos de otro cliente, una ruta de actualización sin comprobación de propiedad. Como la petición está bien formada, parece tráfico normal y se cuela tanto ante los escáneres como ante la detección de intrusiones.
¿Por qué SAST o SCA no pueden atrapar las vulnerabilidades de lógica de negocio?
Porque ambas herramientas razonan sobre el código, y una regla de negocio vive fuera del código. SAST sigue datos no confiables hasta un sumidero peligroso, que es un problema con forma de sintaxis. Una comprobación de autorización ausente no tiene entrada contaminada ni sumidero, solo una guarda que nunca se escribió, y no puedes emparejar por patrón la ausencia de una regla que nunca le dieron al escáner. SCA solo compara tus dependencias contra una base de datos de CVE. Ninguna se construyó para conocer tu modelo de autorización ni tu frontera de tenant.
¿Por qué los agentes de código IA producen más fallos de lógica de negocio?
Porque generan el promedio estadístico del código similar, y el endpoint promedio en internet no aplica tus reglas específicas. Cuando se le pide escribir un manejador de actualización, un agente produce uno que carga una fila y la guarda, ya que ese es el patrón común, sin la comprobación de propietario o el filtro de tenant que tu dominio requiere. La salida es fluida y parece correcta, lo que la hace pasar la revisión, y los agentes generan mucho más código al día del que nadie lee con detenimiento.
¿Cuáles son los fallos de lógica de negocio más comunes en el código generado por IA?
Los recurrentes son la autorización rota (una ruta de escritura sin comprobación de propiedad), las referencias directas inseguras a objetos o IDOR (cambiar un id en la URL para acceder al objeto de otra persona), el alcance de tenant ausente (una consulta filtrada por id pero no por tenant) y el abuso de cantidad o dinero (cantidades negativas o cero, redondeo de float, un precio recalculado a cero en el pago). Las condiciones de carrera en flujos de varios pasos son una quinta clase. Todos ellos pasan una ejecución limpia de SAST y SCA.
¿Cómo previenes los fallos de lógica de negocio en lugar de solo detectarlos?
Mueves la comprobación a antes de que se escriba el código. Si el agente conoce tus reglas, usa un tipo de dinero, encamina las escrituras por una comprobación de propiedad, acota cada consulta al tenant, en el momento en que genera el manejador, escribe la versión protegida al primer intento y el fallo nunca existe. Un escáner a posteriori solo puede marcar lo que ya está en el diff, lo que sigue dependiendo de que una persona rechace código de apariencia fluida. Cargar las reglas en el agente hace del patrón seguro el valor por defecto.
¿Esto reemplaza a mi escáner SAST y SCA?
No, los complementa. SAST sigue siendo la herramienta correcta para la inyección y el análisis de contaminación, y SCA sigue siendo la herramienta correcta para las dependencias vulnerables; ambas resuelven bien los problemas con forma de sintaxis y con forma de dependencia. Los fallos de lógica de negocio son un problema con forma de intención que esas herramientas no pueden ver por diseño. El cuadro completo son tus escáneres existentes para sintaxis y CVE, más una capa en agent-time que lleva tus reglas de negocio al momento de la generación.
¿Cómo conoce VibeDefend mis reglas de negocio sin leer mi código?
Extrae las reglas que ya existen en tu repositorio, el tipo de dinero que usas, el ayudante de autorización que llaman tus rutas de escritura, la columna de tenant en tus consultas, y las convierte en metadatos de gobierno. Solo esos metadatos se usan para dirigir al agente; el código fuente en sí nunca cruza la red, y los tenants de EU y US están aislados para que tus datos permanezcan en tu región. El resultado es un agente que aplica tus convenciones como valores por defecto antes de cada edición, en lugar de un escáner que inspecciona tu código a posteriori.