On this page
- What is AI coding agent security?
- Why is an AI coding agent a new attack surface?
- Why does post-PR scanning fail for AI agents?
- What is agent-time security?
- What are the top risks across AI coding agents?
- How do you secure an AI coding agent in practice?
- Which controls belong at agent-time vs CI?
- Frequently asked questions
- What is agent-time security?
- How is AI coding agent security different from sandboxing?
- Why does post-PR scanning fail for AI agents?
- Does agent-time security replace SAST and CI scanning?
- Which AI coding agents does this apply to?
- What is the biggest AI coding agent security risk?
- How fast can I secure my AI coding agent?
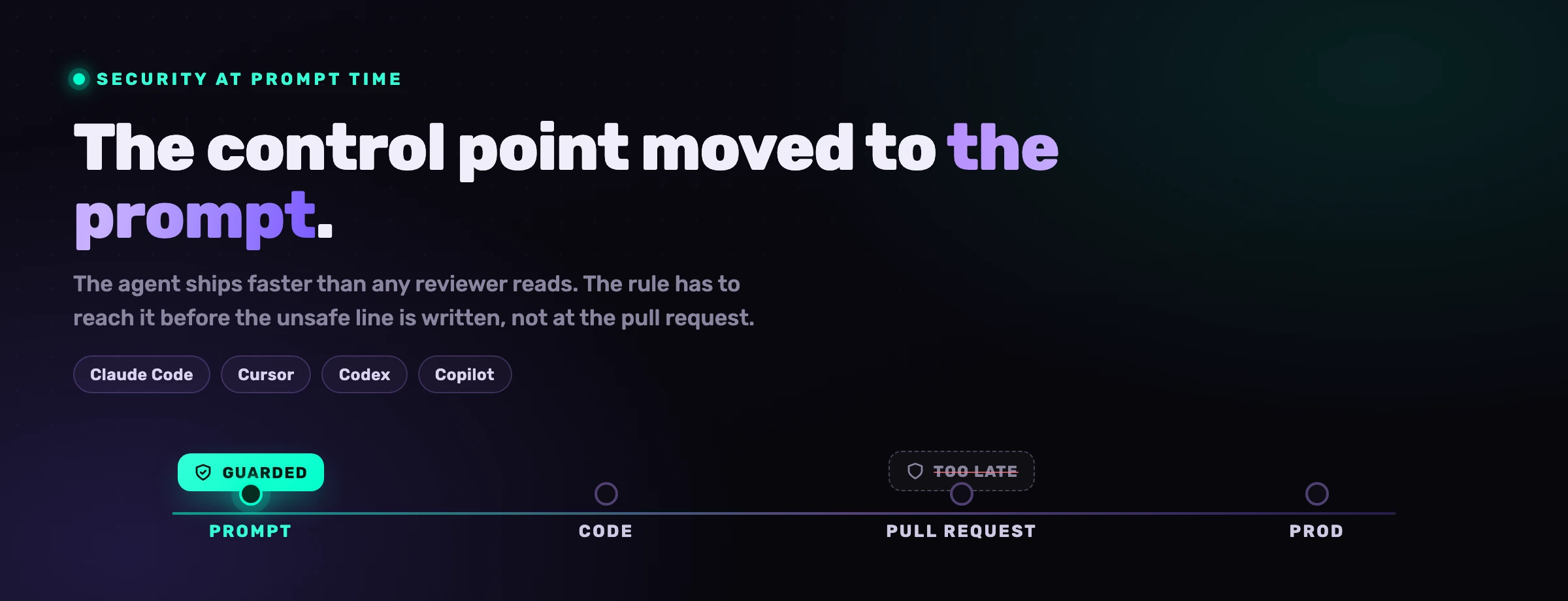
Security review is breaking, and not because reviewers got worse. It is breaking because no human reads 5,000 lines of code a day, and that is now an ordinary output for one developer running an AI coding agent. The pull request became the home of AppSec when a person still slowed down to read the diff. When the agent ships faster than anyone can review, the diff stops being a checkpoint and becomes a transcript of decisions already made. The control point has to move.
What is AI coding agent security?
AI coding agent security is the discipline of constraining what an autonomous coding agent produces and executes, across generation, command execution and tool calls, rather than only securing the box it runs in. It spans the code the agent writes, the dependencies it pulls, the secrets it can read, and the actions it can take on your behalf.
The phrase is often read too narrowly. Most of the published guidance treats it as an infrastructure problem: put the agent in a sandbox, scope its IAM role, limit its network egress, gate its permissions. Those controls are necessary and we are not arguing against them. But they answer a different question. Sandboxing decides what the agent is allowed to touch. It says nothing about whether the SQL the agent just wrote concatenates user input into a query string, or whether the authorization check it skipped will leak another tenant's data. The runtime is contained; the artifact is not. Securing an AI coding agent has to include securing what it writes, at the moment it writes it.
Why is an AI coding agent a new attack surface?
An AI coding agent is a new attack surface because it takes actions instead of suggesting them. A traditional IDE assistant proposes a completion a human chooses to paste. An agent reads files you did not name, runs commands you did not type, edits code across the tree, and calls tools you wired up weeks ago. The blast radius is no longer one block of code.
Two shifts compound that. The first is autonomy: the agent can be steered. Because a language model cannot reliably tell a trusted instruction from a hostile one buried in data, an attacker can hide instructions in a file, a web page, an issue, or a tool's response, and the agent follows them. That is indirect prompt injection, and it is OWASP's number-one risk for LLM applications three years running. A steered assistant answers wrong; a steered agent acts.
The second shift is speed, and it is the one most teams underestimate. The pull request worked as a security gate because it sat at human cadence. The agent does not run at human cadence. When one session ships more code in an afternoon than a reviewer reads in a week, every control that lives only at the PR is now reviewing history rather than preventing it.
prompt injection, the top risk in the OWASP Top 10 for LLM Applications (LLM01)
ordinary output for one developer running an AI coding agent
cost to fix a flaw in production versus catching it at the prompt (IBM Systems Sciences Institute, widely cited shift-left economics)
Why does post-PR scanning fail for AI agents?
Post-PR scanning fails for AI agents because it was designed for human cadence and the agent broke the cadence. SAST, SCA and the human reviewer all act on the same artifact, the diff, and all of them assume a person slows down to read it before merge. When the agent outpaces the reviewer, that assumption no longer holds.
The failure is not that scanners stop finding bugs. They still find them. The failure is timing and volume. By the time a scanner flags an injection in the merged diff, the agent wrote the line, moved on, built three features on top of it, and a developer has a queue of findings to triage that grows faster than anyone can clear it. Teams respond in two predictable ways, both bad: some merge the agent's output with a glance, and some batch it into one giant PR no human reads end to end. Either way the diff has stopped being a gate. It is a record of what already happened.
There is a deeper mismatch too. The most damaging things an AI agent gets wrong are not the patterns scanners are good at. They are business logic flaws: a missing ownership check, a discount that stacks when it should not, a state transition that should never have been reachable. A scanner that does not know your domain cannot see them, and a reviewer drowning in agent output will not catch them either. The control has to know your rules, and it has to act before the line is written.
What is agent-time security?
Agent-time security is the practice of enforcing your controls inside the AI coding agent's loop, before the offending line is written, instead of after the code lands in a pull request. The control point moves from the diff to the prompt. The agent reads the relevant rules as part of writing the code, so the requirement becomes part of the output rather than a checkbox at audit time.
It is the natural answer to the cadence problem. If the agent ships faster than you can review, you do not win by reviewing harder. You win by putting the rule in the agent's hands before it acts. Concretely, agent-time security hooks the agent's session and tool calls: before an edit, it injects the conventions and security requirements that apply to the files being touched; before a destructive command fires, it intercepts. Nothing waits for merge.
The pull request was a control point because a human read it. The prompt is the control point now because the agent listens to it. Agent-time security is the layer that puts the agent's listener on your side.
This does not replace your scanners. SAST and SCA still belong in CI as the backstop for anything that slips, and for code humans still write by hand. Agent-time security is the layer in front of them, the one that matches the speed of the thing actually generating the code.
What are the top risks across AI coding agents?
The top risks are consistent across Claude Code, Cursor, GitHub Copilot, OpenAI Codex and Windsurf, because they share the same agentic shape. The per-agent guides cover each tool's native controls in detail; the risk classes themselves rhyme.
- Insecure generated code. The agent writes injectable queries, weak crypto, missing authorization, and unsafe deserialization, because those patterns are abundant in its training data. This is the risk the infrastructure framing ignores entirely.
- Business logic flaws. Missing ownership checks, broken access control between tenants, state machines that allow illegal transitions. Invisible to generic scanners, common in agent output.
- Prompt injection, direct and indirect. Hostile instructions hidden in a repo, a web page, an issue, or an MCP tool response that the agent treats as a command. OWASP LLM01.
- Over-permissioned tools and MCP servers. A database tool scoped to read everything, a filesystem server pointed at the home directory, a deploy tool holding production credentials. Tool poisoning hides instructions in tool descriptions, so simply connecting a server can steer the agent.
- Supply chain and dependency risk. The agent installs packages and runs setup scripts as normal work. Typosquatting and package hallucination turn a routine "set up this repo" into credential theft.
- Secrets and context exposure. Broad local context (
.envfiles, credentials, internal endpoints) gets surfaced in logs, generated code, or a PR that outlives the session. - Destructive actions. A manipulated agent runs
sudo rm -rf, rewrites a CI config, or alters infrastructure, with whatever access the environment granted it.
How do you secure an AI coding agent in practice?
You secure an AI coding agent by combining runtime containment with agent-time governance, then keeping CI as the backstop. Least privilege, sandboxing, secrets management and human review are table stakes. The piece most stacks are missing is a control that lives at the prompt and governs what the agent writes before it writes it.
In practice that means a defense-in-depth posture with the control point pulled forward. Scope the agent's permissions and isolate its runtime so a steered agent has a small blast radius. Manage secrets so the agent's context is no broader than the task needs. Keep SAST and dependency scanning in CI for everything that slips and for human-written code. Then add the layer that actually matches the agent's speed: governance inside the loop, where the agent reads your business rules and security requirements as it codes, and a guard intercepts destructive calls before they fire. The three agent-time layers below are what that control looks like.
Business Rules
The conventions that are real in your repo but were never written down. Money uses Decimal128, never a float. Authorization goes through requireOwner, not a raw membership check. Soft-deleted records never leave the boundary. These get mined from how your team already codes and pushed into the agent's context before the relevant edit, so the agent writes the convention on the first try.
Security Rules
OWASP, SOC 2, GDPR and ISO 27001, the frameworks your auditors already expect, loaded the day you install and matched per edit. The agent reads the applicable requirement before each write, so the control becomes part of the code instead of a finding to triage at merge.
Action Guard
sudo rm -rf, raw process.env reads on secret-shaped keys, ad-hoc psql against a production-looking host. The guard intercepts the agent's call before it fires, blocks or warns per rule, and lands every interception in an audit trail. This is the layer that turns a destructive action back into a draft.
Which controls belong at agent-time vs CI?
Controls belong at agent-time when they govern an action the agent is about to take, and at CI when they are a backstop on the finished artifact. The rule of thumb: if a human reviewing the diff would be too late, the control has to run inside the loop. If it is a final gate before merge or deploy, it stays in CI.
Read the two columns as partners, not rivals. CI scanning is still the right place for a final, artifact-level check, and you should keep it. Agent-time is where you move the controls that lose all their value the moment the agent has finished and moved on. The mistake the SERP makes is funding only the right column's infrastructure cousin (sandbox, IAM) while leaving the actual code ungoverned until merge.
VibeDefend is the agent-time layer, packaged as a free npm CLI that installs in about five seconds. One command auto-detects Claude Code, Cursor, OpenAI Codex, Windsurf and VS Code Copilot on your machine and wires each one into three governance layers that run inside the agent loop. No YAML, no deploy, no container to build.

The three layers map exactly to the model above. Business Rules are mined from how your team already codes and proposed as explicit one-line rules. Security Rules load the frameworks your auditors expect and match them per edit. The Action Guard intercepts destructive calls before they fire. The privacy model is the part security teams care about most: nothing about your code crosses the wire. The decisions happen locally, next to the agent, and only structured governance metadata reaches the backend, the rule that fired, the file path it pointed at, the severity, a timestamp. No source code, no prompt contents. EU and US tenants are physically separate and chosen at install, with no cross-region path.
Frequently asked questions
What is agent-time security?
Agent-time security is enforcing your controls inside the AI coding agent's loop, before the offending line is written, instead of after the code reaches a pull request. The control point moves from the diff to the prompt: the agent reads the rules that apply as it writes, so the requirement becomes part of the output. It is the response to agents shipping code faster than any human can review.
How is AI coding agent security different from sandboxing?
Sandboxing secures where the agent runs; AI coding agent security also has to secure what the agent writes. A sandbox can perfectly contain the runtime and still let the agent write an injectable query or skip an authorization check, because the unsafe artifact is not a runtime concern. You need both: containment for the blast radius, and agent-time governance for the code itself.
Why does post-PR scanning fail for AI agents?
Because it assumes a human slows down to read the diff before merge, and the agent broke that cadence. Scanners still find bugs, but findings queue faster than teams can triage, so people either merge with a glance or batch everything into one unreadable PR. The diff stops being a gate. The control has to move into the loop, ahead of merge.
Does agent-time security replace SAST and CI scanning?
No. SAST and dependency scanning stay in CI as the backstop for anything that slips and for human-written code. Agent-time security is the layer in front of them, matching the speed of the agent generating the code. Think of them as partners: agent-time is front-line governance of agent output, CI is the final artifact-level gate.
Which AI coding agents does this apply to?
The same risk classes and the same agent-time model apply across Claude Code, Cursor, GitHub Copilot, OpenAI Codex and Windsurf, because they share an agentic shape: they read, write, run and call tools. The per-agent guides cover each tool's native controls and where they fall short.
What is the biggest AI coding agent security risk?
Two stand out. Prompt injection is OWASP's number-one LLM risk because a model cannot reliably separate a trusted instruction from a hostile one hidden in data, and a steered agent acts rather than just answering wrong. The quieter one is business logic flaws in generated code: missing ownership checks and broken access control that generic scanners cannot see and overloaded reviewers miss.
How fast can I secure my AI coding agent?
About five seconds for the install and roughly a minute end to end. Run npx -y @cybedefend/vibedefend@latest install, pick EU or US, confirm the agent you use, and drop a one-line .cybedefend/config.json in the repo. The next prompt is governed by the three layers. The free tier needs no card, or you can book a session to run it on your own code.