Auf dieser Seite
- Was ist eine Business-Logik-Schwachstelle?
- Warum kann SAST Business-Logik-Schwachstellen nicht finden?
- Warum produzieren KI-Coding-Agenten mehr davon?
- Wie sehen Business-Logik-Schwachstellen in KI-Code aus?
- Wie fängt man Business-Logik-Schwachstellen zum Agent-Time ab?
- Wie unterscheidet sich das von SAST und SCA?
- Häufig gestellte Fragen
- Was ist eine Business-Logik-Schwachstelle in einfachen Worten?
- Warum können SAST oder SCA Business-Logik-Schwachstellen nicht abfangen?
- Warum produzieren KI-Coding-Agenten mehr Business-Logik-Schwachstellen?
- Was sind die häufigsten Business-Logik-Schwachstellen in KI-generiertem Code?
- Wie verhindert man Business-Logik-Schwachstellen, statt sie nur zu erkennen?
- Ersetzt das meinen SAST- und SCA-Scanner?
- Wie kennt VibeDefend meine Geschäftsregeln, ohne meinen Code zu lesen?
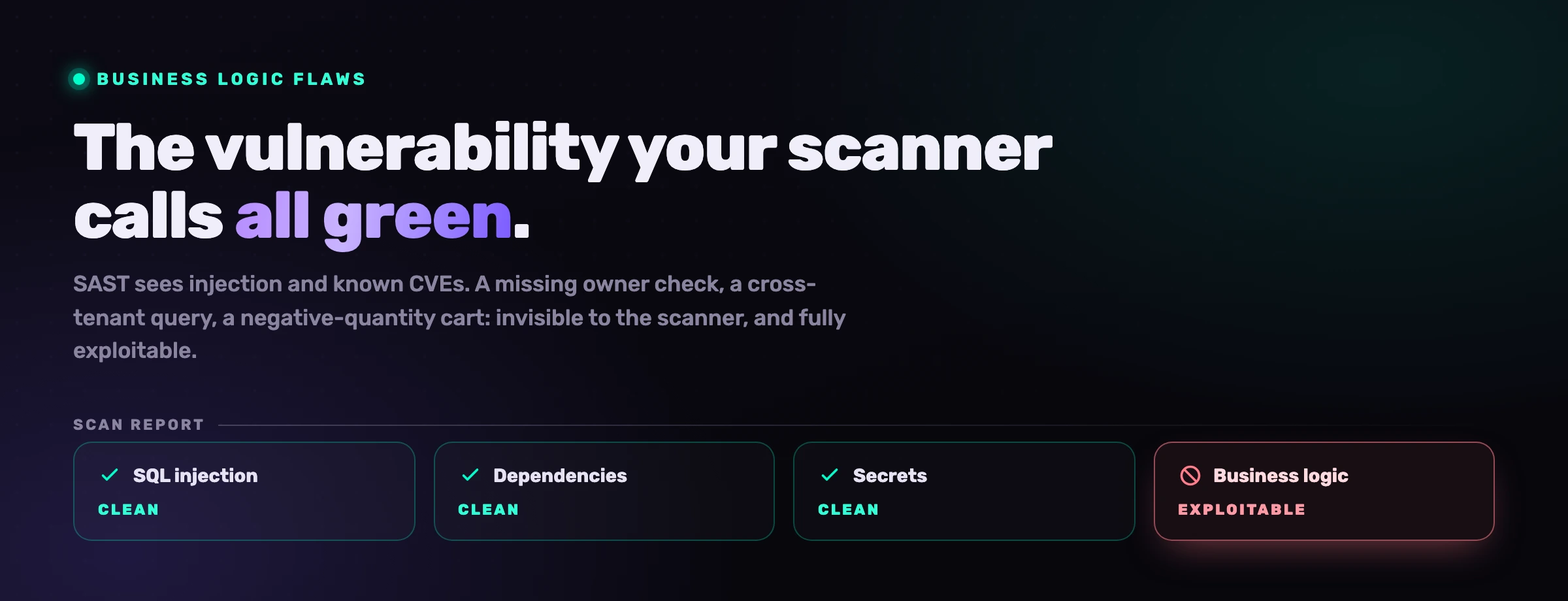
Ihr SAST-Scanner kann eine SQL-Injection in einem String finden, den er nie zuvor gesehen hat. Er kann Ihnen nicht sagen, dass Ihr neuer Checkout-Endpunkt einem Kunden erlaubt, eine negative Menge zu setzen und mit Geld davonzugehen. Das erste ist ein Syntaxmuster. Das zweite ist eine Geschäftsregel, und Ihrem Scanner wurde nie gesagt, was Ihre Geschäftsregeln sind. KI-Coding-Agenten verschlimmern diese Lücke, weil sie plausiblen Code generieren, der das Framework perfekt mustererkennt und dabei stillschweigend die Regel bricht, auf die es ankommt.
Was ist eine Business-Logik-Schwachstelle?
Eine Business-Logik-Schwachstelle ist eine Verwundbarkeit, bei der der Code syntaktisch korrekt ist, frei von Injection und auf gepatchten Bibliotheken aufgebaut, und dennoch eine Regel verletzt, die Ihre Anwendung durchsetzen soll. Die klassischen Beispiele sind kaputte Autorisierung, fehlendes Mandanten-Scoping, Integer- oder Mengenmissbrauch, unsichere direkte Objektreferenzen (IDOR) und Reihenfolge-Races. Nichts ist fehlerhaft geformt. Die Logik liegt einfach falsch darüber, was erlaubt ist.
Das ist die Kategorie, die OWASP als Business Logic Vulnerabilities verfolgt und, für den Autorisierungs-Teil, als Broken Access Control, das Risiko Nummer eins in der OWASP Top 10. Diese Schwachstellen sind gerade deshalb gefährlich, weil sie wie normaler Verkehr aussehen. Es gibt keine fehlerhafte Nutzlast, keinen Stack-Trace, keine Signatur, die ein Intrusion-Detection-System abgleichen könnte. Die Anfrage ist wohlgeformt; sie hätte einfach nicht honoriert werden dürfen. Wir sind eine davon von Anfang bis Ende durchgegangen in dem 0-Euro-Warenkorb: eine perfekte CI/CD-Pipeline, jedes Dashboard grün, und ein ganzes Inventar für nichts ausgecheckt.
Warum kann SAST Business-Logik-Schwachstellen nicht finden?
Weil SAST über Code argumentiert, und eine Geschäftsregel lebt außerhalb des Codes. Ein statischer Analysator kann verseuchte Daten von einer Quelle zu einer Senke verfolgen und beweisen, dass eine Injection erreichbar ist. Er hat keine Quelle für die Tatsache, dass "nur der Eigentümer eines Dokuments es bearbeiten darf" oder "Menge muss eine positive ganze Zahl sein". Diese Regeln stecken in Ihrem Kopf, Ihren Tickets und Ihrer Domäne, nicht in irgendeinem Muster, das der Scanner mitbringt.
Das ist eine strukturelle Grenze, keine Reifelücke, die ein neuerer Scanner schließt. SAST glänzt bei der Taint-Analyse: nicht vertrauenswürdige Eingabe, gefährliche Senke, kein Sanitizer dazwischen. Eine fehlende Autorisierungsprüfung ist die gegenteilige Gestalt. Es gibt keine verseuchte Eingabe und keine gefährliche Senke, nur eine if-Anweisung, die nie geschrieben wurde. Sie können das Fehlen einer Regel, die Ihnen nie gegeben wurde, nicht mustererkennen. Das ist auch, warum die meisten Teams in Scanner-Ausgaben ertrinken, die das echte Risiko verfehlen, das Thema von warum die meisten SAST-Befunde Rauschen sind. Das richtige mentale Modell ist ein Eisberg.
- Injection: SQL, Command, XSS, SSRF, mit einem klaren Pfad von Quelle zu Senke
- Bekannte CVEs in Drittparteien-Abhängigkeiten (SCA)
- Fest codierte Geheimnisse und offensichtliche Fehlkonfiguration
Mengen- und Geldmissbrauch
Negative oder Null-Menge, Float-Rundung, ein Preis, der beim Checkout auf null neu berechnet wird.
Kaputte Autorisierung
Eine Update- oder Delete-Route, die nie prüft, ob der Aufrufer den Datensatz tatsächlich besitzt.
IDOR
Tauschen einer ID in der URL, um ein Objekt zu lesen oder zu verändern, das jemand anderem gehört.
Fehlendes Mandanten-Scoping
Eine Query, gefiltert nach ID, aber nicht nach Mandant, die die Zeilen eines anderen Kunden zurückgibt.
Alles unterhalb der Wasserlinie besteht einen sauberen SAST- und SCA-Lauf. Der Code kompiliert, die Bibliotheken sind aktuell, keine Injection ist erreichbar. Der Bericht ist ganz grün, und die Anwendung ist ausnutzbar.
Warum produzieren KI-Coding-Agenten mehr davon?
Weil ein KI-Agent ein Mustererkenner ist, trainiert auf der Gestalt von funktionierendem Code, und eine Geschäftsregel ist keine Gestalt. Wenn Sie einen Agenten bitten, "einen Endpunkt zum Aktualisieren eines Projekts hinzuzufügen", produziert er einen Handler, der die ID parst, die Zeile lädt und die Änderung speichert, weil das ist, was Millionen korrekt aussehender Handler tun. Er hat keinen Grund, eine Eigentümerprüfung oder einen Mandantenfilter hinzuzufügen, da diese spezifisch für Ihre Domäne sind und im generischen Muster fehlen.
Die Schwachstelle ist also kein Fehler, den das Modell aus Versehen einführt; sie ist das vorhersehbare Ergebnis davon, den Durchschnitt allen ähnlichen Codes zu generieren. Der durchschnittliche Update-Endpunkt im Internet setzt Ihr Autorisierungsmodell nicht durch. Schlimmer noch, die Ausgabe ist flüssig und selbstbewusst, was genau das ist, was sie die Prüfung bestehen lässt. Ein Prüfer überfliegt einen Handler, der wie jeder andere Handler aussieht, und genehmigt ihn. In Maschinengeschwindigkeit generieren Agenten jetzt tausende Zeilen pro Tag, weit mehr, als irgendein Mensch von Anfang bis Ende liest, sodass die Lücke zwischen "sieht richtig aus" und "ist richtig" ist, wo sich die Sicherheitsverletzungen anhäufen. Wir behandeln die breitere Risikofläche in unserem Leitfaden zur Sicherheit von KI-Coding-Agenten.
Ein Scanner fragt: "Ist diese Zeile gefährlich?" Eine Business-Logik-Schwachstelle antwortet "nein" und wird trotzdem ausgenutzt. Die richtige Frage ist: "Befolgt dieser Code die Regeln dieser Codebasis?", und kein Syntax-Tool wurde je gebaut, um sie zu beantworten.
Wie sehen Business-Logik-Schwachstellen in KI-Code aus?
Sie sehen aus wie sauberer, idiomatischer Code mit einem fehlenden Schutz. Hier sind drei Klassen, die ein Agent routinemäßig ausliefert. Jede kompiliert, jede besteht SAST, und jede ist ein kritischer Befund.
Warenkorb mit negativer Menge. Bitten Sie um einen "In den Warenkorb"-Endpunkt, und Sie bekommen Arithmetik ohne Domänenbeschränkung. Eine Menge von -1 zieht vom Gesamtbetrag ab.
// Vulnerable: no constraint on quantity
function addToCart(cart, item, quantity) {
cart.total += item.price * quantity; // quantity = -1 lowers the total
return cart;
}
// Fixed: enforce the business rule
function addToCart(cart, item, quantity) {
if (!Number.isInteger(quantity) || quantity < 1) {
throw new ValidationError("quantity must be a positive integer");
}
cart.total += item.price * quantity;
return cart;
}
Fehlende Autorisierung / IDOR. Bitten Sie um eine "Projekt aktualisieren"-Route, und Sie bekommen einen Handler, der per ID lädt und speichert. Jeder authentifizierte Benutzer kann jede beliebige ID übergeben.
# Vulnerable: loads by id, never checks ownership (IDOR)
@app.put("/projects/{project_id}")
def update_project(project_id, body, user):
project = db.get(Project, project_id)
project.name = body.name
db.commit()
return project
# Fixed: require the caller to own the record
@app.put("/projects/{project_id}")
def update_project(project_id, body, user):
project = db.get(Project, project_id)
require_owner(project, user) # 403 if user.id != project.owner_id
project.name = body.name
db.commit()
return project
Fehlendes Mandanten-Scoping. In einer mandantenfähigen App leckt eine Query, die nur nach ID gefiltert ist, über Mandanten hinweg.
# Vulnerable: filtered by id only, crosses tenant boundary
invoice = db.query(Invoice).filter(Invoice.id == invoice_id).first()
# Fixed: scope every query to the caller's tenant
invoice = db.query(Invoice).filter(
Invoice.id == invoice_id,
Invoice.tenant_id == user.tenant_id,
).first()
In allen dreien ist der Unterschied zwischen sicher und ausnutzbar eine Zeile, die eine Regel kodiert, die der Agent unmöglich kennen konnte. Der Fall mit negativer Menge ist für sich allein auch eine vollständige Exploit-Kette.
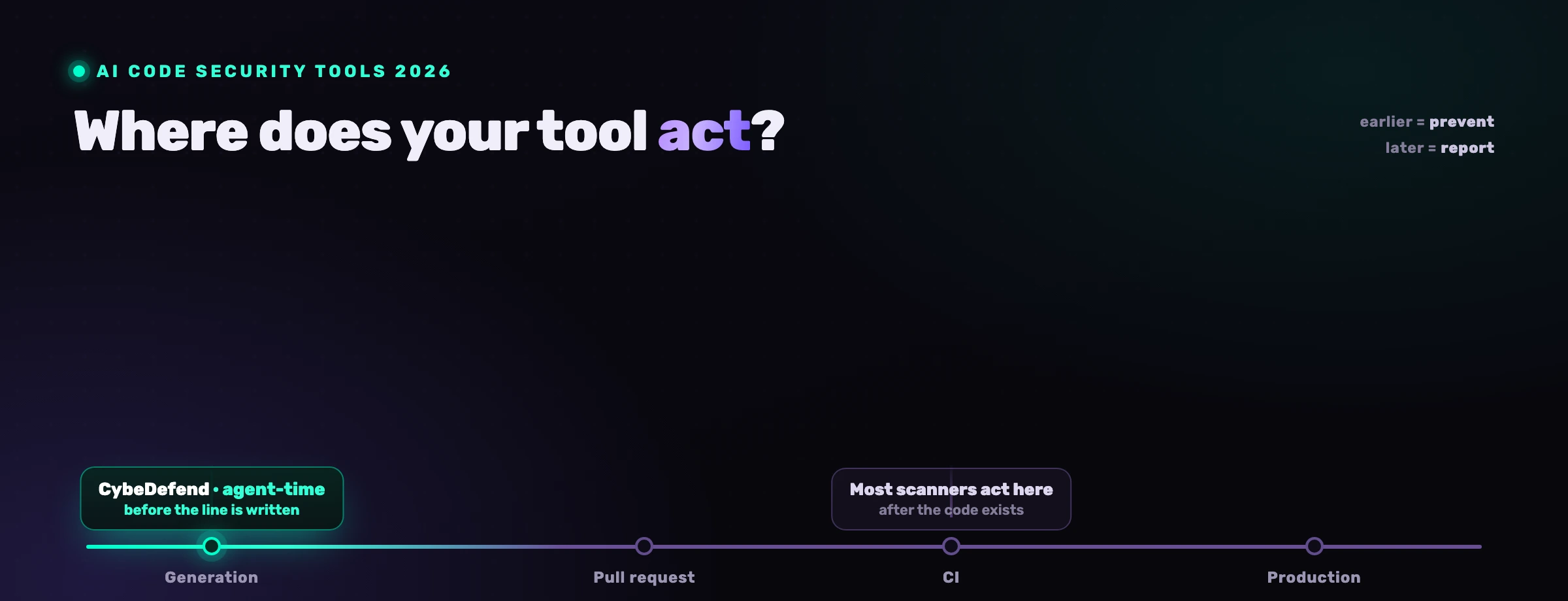
Wie fängt man Business-Logik-Schwachstellen zum Agent-Time ab?
Sie fangen sie ab, indem Sie dem Agenten Ihre Regeln geben, bevor er schreibt, nicht indem Sie scannen, nachdem er ausliefert. Wenn der Agent "Geld verwendet Decimal, jeder Schreibvorgang läuft über requireOwner, jede Query ist auf tenant_id begrenzt" in dem Moment kennt, in dem er den Handler generiert, schreibt er die geschützte Version beim ersten Versuch. Die Schwachstelle wird nie erzeugt, also gibt es nichts, das später zu finden, zu sichten oder zu beheben wäre.
Das ist der zentrale Schritt: Verschieben Sie die Prüfung links vom Tastenanschlag. Ein nachträglicher Scanner kann nur markieren, was bereits im Diff existiert, was bedeutet, dass ein Mensch immer noch flüssig aussehenden Code unter Zeitdruck lesen, verstehen und ablehnen muss. Das Laden der Regeln in den Kontext des Agenten verwandelt die Regel in einen Standardwert. Der Agent hört auf, den durchschnittlichen Endpunkt zu produzieren, und beginnt, Ihren Endpunkt zu produzieren. Für Domänen, in denen diese Schwachstellen am teuersten sind, Banking und Fintech, ist die Durchsetzung zum Agent-Time der Unterschied zwischen einem Schutz, der per Design existiert, und einem, der davon abhängt, dass ein Prüfer sein Fehlen abfängt.
Wie unterscheidet sich das von SAST und SCA?
Es ist eine andere Ebene des Problems. SAST und SCA beantworten "ist dieser Code gefährlich oder veraltet?" Die Regel-Durchsetzung zum Agent-Time beantwortet "befolgt dieser Code die Regeln dieser Codebasis?" Sie wollen beides: Behalten Sie SAST für Injection und Taint, behalten Sie SCA für verwundbare Abhängigkeiten und fügen Sie eine Ebene hinzu, die Ihre Geschäftsregeln in den Moment der Generierung trägt.
Der klassische Stack ist notwendig und nicht hinreichend. Er wurde für ein syntaxförmiges Problem gebaut und bleibt das richtige Tool für dieses Problem. Business-Logik-Schwachstellen sind ein absichtsförmiges Problem, und sie brauchen eine Ebene, die Ihre Absicht kennt.
VibeDefend ist diese Ebene. Es fördert die Geschäftsregeln, die bereits in Ihrem Repository vorhanden sind, und lädt sie vor jeder Bearbeitung in Ihren KI-Coding-Agenten, sodass der Agent Code schreibt, der Ihre Autorisierungs-, Geld- und Mandantenregeln vom ersten Tastenanschlag an respektiert. Es ist eine kostenlose npm-CLI und installiert sich in etwa fünf Sekunden.

Die Business-Rules-Ebene wird aus Ihrem eigenen Repository gefördert, verwende Decimal für Geld, leite jeden Schreibvorgang durch requireOwner, begrenze jede Query auf den Mandanten, und wird vor jeder Bearbeitung in den Agenten geladen. Eine vierte Ebene, Live Findings, verdrahtet den Agenten in CybeDefends vollständige AppSec-Plattform, sodass jedes Ergebnis aus ihren Scannern (SAST mit Erreichbarkeit, SCA, Secrets, IaC und CI/CD) live im Kontext des Agenten ist, um es zu triagieren und zu beheben, nicht nur die Business-Logik-Regeln, gegen die er schreibt. Das Datenschutzmodell ist streng: Nichts über Ihren Code geht über die Leitung, nur Governance-Metadaten, und EU- und US-Mandanten werden getrennt gehalten, sodass Ihre Daten in Ihrer Region bleiben.
Häufig gestellte Fragen
Was ist eine Business-Logik-Schwachstelle in einfachen Worten?
Es ist Code, der genau wie geschrieben funktioniert, aber etwas tut, das er nicht erlauben sollte. Die Syntax ist gültig, es gibt keine Injection, und die Bibliotheken sind gepatcht, dennoch bricht die Anwendung eine ihrer eigenen Regeln: ein Warenkorb, der eine negative Menge akzeptiert, ein Endpunkt, der die Daten eines anderen Kunden zurückgibt, eine Update-Route ohne Eigentümerprüfung. Da die Anfrage wohlgeformt ist, sieht sie wie normaler Verkehr aus und rutscht gleichermaßen an Scannern und Intrusion Detection vorbei.
Warum können SAST oder SCA Business-Logik-Schwachstellen nicht abfangen?
Weil beide Tools über den Code argumentieren, und eine Geschäftsregel lebt außerhalb des Codes. SAST verfolgt nicht vertrauenswürdige Daten zu einer gefährlichen Senke, was ein syntaxförmiges Problem ist. Eine fehlende Autorisierungsprüfung hat keine verseuchte Eingabe und keine Senke, nur einen Schutz, der nie geschrieben wurde, und Sie können das Fehlen einer Regel, die dem Scanner nie gegeben wurde, nicht mustererkennen. SCA vergleicht Ihre Abhängigkeiten nur gegen eine CVE-Datenbank. Keines wurde gebaut, um Ihr Autorisierungsmodell oder Ihre Mandantengrenze zu kennen.
Warum produzieren KI-Coding-Agenten mehr Business-Logik-Schwachstellen?
Weil sie den statistischen Durchschnitt ähnlichen Codes generieren, und der durchschnittliche Endpunkt im Internet setzt Ihre spezifischen Regeln nicht durch. Gebeten, einen Update-Handler zu schreiben, produziert ein Agent einen, der eine Zeile lädt und speichert, da das das gängige Muster ist, ohne die Eigentümerprüfung oder den Mandantenfilter, den Ihre Domäne erfordert. Die Ausgabe ist flüssig und sieht korrekt aus, was sie die Prüfung bestehen lässt, und Agenten generieren weit mehr Code pro Tag, als irgendjemand genau liest.
Was sind die häufigsten Business-Logik-Schwachstellen in KI-generiertem Code?
Die wiederkehrenden sind kaputte Autorisierung (ein Schreibpfad ohne Eigentümerprüfung), unsichere direkte Objektreferenzen oder IDOR (Ändern einer ID in der URL, um auf das Objekt eines anderen zuzugreifen), fehlendes Mandanten-Scoping (eine Query, gefiltert nach ID, aber nicht nach Mandant) und Mengen- oder Geldmissbrauch (negative oder Null-Mengen, Float-Rundung, ein Preis, der beim Checkout auf null neu berechnet wird). Race-Conditions bei mehrstufigen Abläufen sind eine fünfte Klasse. Alle bestehen einen sauberen SAST- und SCA-Lauf.
Wie verhindert man Business-Logik-Schwachstellen, statt sie nur zu erkennen?
Sie verschieben die Prüfung auf vor das Schreiben des Codes. Wenn der Agent Ihre Regeln kennt, verwende einen Geldtyp, leite Schreibvorgänge durch eine Eigentümerprüfung, begrenze jede Query auf den Mandanten, in dem Moment, in dem er den Handler generiert, schreibt er die geschützte Version beim ersten Versuch, und die Schwachstelle existiert nie. Ein nachträglicher Scanner kann nur markieren, was bereits im Diff ist, was immer noch davon abhängt, dass ein Mensch flüssig aussehenden Code ablehnt. Das Laden von Regeln in den Agenten macht das sichere Muster zum Standardwert.
Ersetzt das meinen SAST- und SCA-Scanner?
Nein, es ergänzt sie. SAST bleibt das richtige Tool für Injection und Taint-Analyse, und SCA bleibt das richtige Tool für verwundbare Abhängigkeiten; beide lösen syntaxförmige und abhängigkeitsförmige Probleme gut. Business-Logik-Schwachstellen sind ein absichtsförmiges Problem, das diese Tools per Design nicht sehen können. Das vollständige Bild sind Ihre bestehenden Scanner für Syntax und CVEs plus eine Ebene zum Agent-Time, die Ihre Geschäftsregeln in den Moment der Generierung trägt.
Wie kennt VibeDefend meine Geschäftsregeln, ohne meinen Code zu lesen?
Es fördert die Regeln, die bereits in Ihrem Repository existieren, den Geldtyp, den Sie verwenden, den Autorisierungs-Helper, den Ihre Schreibpfade aufrufen, die Mandantenspalte bei Ihren Queries, und verwandelt sie in Governance-Metadaten. Nur diese Metadaten werden verwendet, um den Agenten zu lenken; der Quellcode selbst geht nie über die Leitung, und EU- und US-Mandanten sind isoliert, sodass Ihre Daten in Ihrer Region bleiben. Das Ergebnis ist ein Agent, der Ihre Konventionen als Standardwerte vor jeder Bearbeitung anwendet, statt eines Scanners, der Ihren Code im Nachhinein inspiziert.