Auf dieser Seite
- Was ist Claude Code, und warum verändert es das Sicherheitsmodell?
- Wie das Sicherheitsmodell von Claude Code funktioniert
- Die 6 größten Sicherheitsrisiken in Claude Code
- 1. Schwache Governance von Genehmigungen und Berechtigungen
- 2. Prompt Injection
- 3. Überprivilegierte MCP-Server und Tool-Vergiftung
- 4. Lieferkette (Supply Chain) und bösartige Abhängigkeiten
- 5. Offenlegung von Geheimnissen und sensiblem Kontext
- 6. Befehlsausführung und Remote-Code-Ausführung
- Was die native Sicherheit von Claude Code abdeckt und was nicht
- Best Practices zur Absicherung von Claude Code
- Wo native Kontrollen aufhören: den Agenten zum Zeitpunkt des Prompts absichern
- Häufig gestellte Fragen
- Ist Claude Code sicher zu verwenden?
- Sendet Claude Code meinen Quellcode in die Cloud?
- Was ist die gefährlichste Claude-Code-Einstellung?
- Kann Claude Code von Prompt Injection getroffen werden?
- Wie sichere ich MCP-Server in Claude Code ab?
- Wie unterscheidet sich die Absicherung von Claude Code von der von GitHub Copilot, Cursor oder Codex?
- Ersetzen die nativen Kontrollen von Claude Code SAST und Code-Review?
- Wie rolle ich Claude Code sicher über ein ganzes Team aus?
Claude Code ist keine Autovervollständigung. Es liest Ihr Repository, bearbeitet Dateien, führt Shell-Befehle aus und ruft externe Tools in Ihrem Namen auf. Genau das macht es nützlich, und genau das macht es zu einer Angriffsfläche, wie sie kein IDE-Assistent jemals war. Seine nativen Berechtigungen, die Sandbox und die verwalteten Einstellungen verringern das Risiko spürbar. Sie beseitigen es nicht. Dieser Leitfaden behandelt die echten Risiken, wovor die nativen Kontrollen tatsächlich schützen, die Best Practices, die die Lücke schließen, und die eine Ebene, die das native Modell stillschweigend voraussetzt.
Was ist Claude Code, und warum verändert es das Sicherheitsmodell?
Claude Code ist das agentische Coding-Tool von Anthropic. Es arbeitet innerhalb der bestehenden Umgebung der Entwickler (das Terminal, die IDE, die Desktop-App, CI) und handelt auf der Grundlage von Anweisungen in natürlicher Sprache: eine Codebasis analysieren, ein Feature generieren, die Tests ausführen, einen Pull Request vorbereiten. Es verbindet sich mit GitHub und GitLab, läuft neben Build-Systemen und Test-Suiten und erweitert sich über das Model Context Protocol (MCP), um Datenbanken, Ticketing-Systeme und interne Tools zu erreichen.
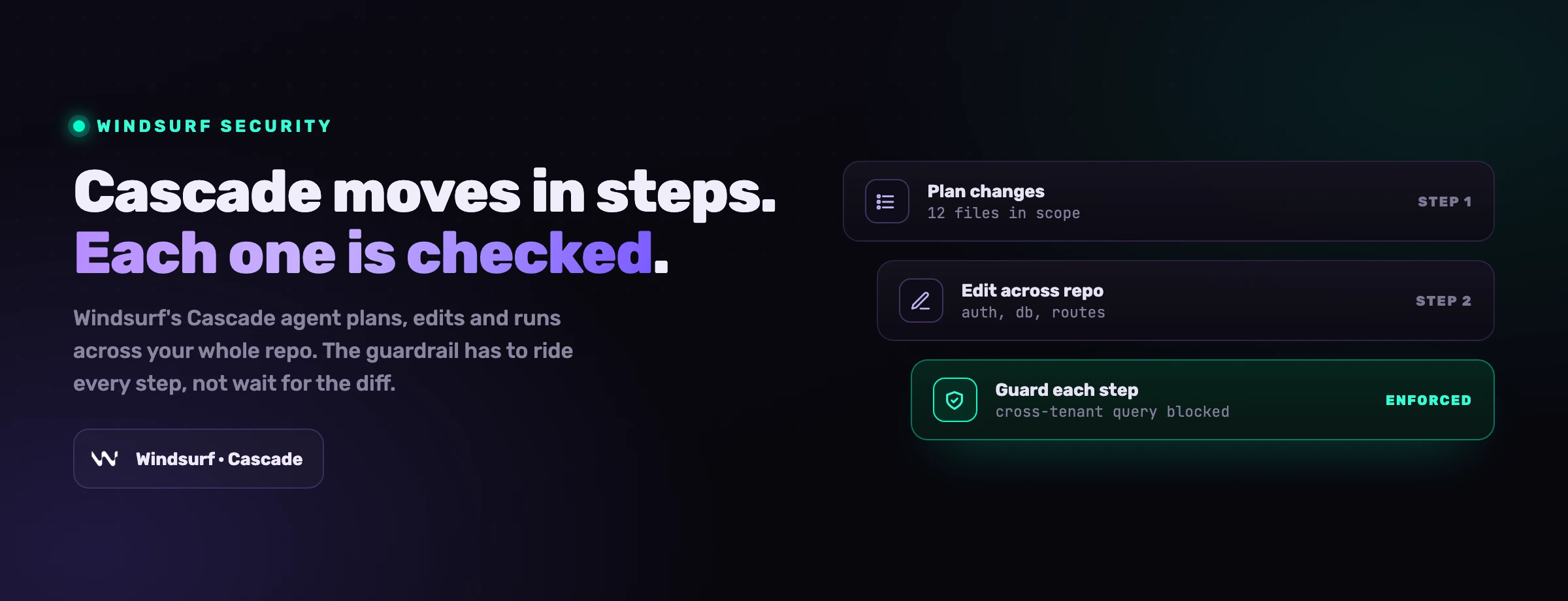
Die letzte Eigenschaft ist diejenige, die das alte Sicherheitsmodell zerbricht. Ein klassischer IDE-Assistent schlägt Vervollständigungen vor; ein Mensch nimmt jede einzelne an oder lehnt sie ab. Der Wirkungsradius eines schlechten Vorschlags ist ein Codeblock, den ein Entwickler trotzdem noch einfügen muss. Claude Code führt stattdessen Aktionen aus. Es liest Dateien, die Sie nicht genannt haben, führt Befehle aus, die Sie nicht getippt haben, bearbeitet Code im gesamten Baum und ruft Tools auf, die Sie vor Wochen eingerichtet und vergessen haben. Die Angriffsfläche ist nicht mehr "welchen Code hat das Modell vorgeschlagen". Sie ist "was kann dieser Agent mit dem Zugriff anstellen, den er hat, und wer darf seine Anweisungen beeinflussen".
Ein Vorschlag ist ein Entwurf, den ein Mensch annimmt. Eine Aktion ist etwas, das bereits geschehen ist. Das Sicherheitsmodell muss sich vom Prüfen von Entwürfen zum Eingrenzen von Aktionen verschieben.
Es gibt eine zweite Verschiebung, die noch wichtiger ist, und sie betrifft die Geschwindigkeit. Der Pull Request wurde zur Heimat der Anwendungssicherheit, weil er im menschlichen Takt lag: Eine Person verlangsamte sich, las das Diff und führte erst dann den Merge durch. Claude Code läuft nicht im menschlichen Takt. Eine einzige Sitzung kann an einem Nachmittag mehr Code ausliefern, als ein Prüfer in einer Woche liest. Wenn das passiert, hört das Diff auf, ein Kontrollpunkt zu sein, und wird zum Protokoll bereits getroffener Entscheidungen. Jede Kontrolle, die nur beim Pull Request greift, prüft jetzt Geschichte, statt sie zu verhindern.
Für die meisten Teams lautet die praktische Frage nicht, ob Claude Code native Schutzmechanismen hat. Es hat sie, und sie sind gut. Die Frage ist, ob diese Schutzmechanismen für den täglichen Gebrauch ausreichen. Die ehrliche Antwort lautet nein. Native Kontrollen, Prüfungen und scan-ähnliche Checks verringern das Risiko, aber eine sichere Einführung hängt weiterhin von Berechtigungen, Sandboxing, Isolation, menschlicher Aufsicht und unabhängiger Validierung über Code, Abhängigkeiten, Geheimnisse und Pipelines hinweg ab. Anthropic sagt in seiner eigenen Sicherheitsdokumentation genau das: Die Kontrollen sind Verteidigungsebenen, kein vollständiges Sicherheitsprogramm.
Wie das Sicherheitsmodell von Claude Code funktioniert
Das Modell von Claude Code baut auf drei Ideen auf: vor jeder riskanten Handlung nachfragen, eingrenzen, was der Agent berühren darf, und das auf Betriebssystemebene durchsetzen, wo es darauf ankommt. In der Praxis zeigt sich das als eine Handvoll Kontrollen.
Gestufte Berechtigungen
Schreibgeschützte Aktionen (Dateilesungen, Suche) laufen ohne Genehmigung. Risikoreichere Aktionen (Shell-Befehle, Dateibearbeitungen, Netzwerkzugriff, MCP-Tools) erfordern sie. Regeln gibt es in drei Ausprägungen, allow, ask und deny, wobei deny immer gewinnt, und sie können auf bestimmte Tools, Befehle, Dateipfade, Domains, MCP-Server oder Arbeitsverzeichnisse begrenzt werden.
Berechtigungsmodi
default, acceptEdits, plan, auto, dontAsk und bypassPermissions. Die Modi tauschen Reibung gegen Geschwindigkeit. Anthropic stellt ausdrücklich klar, dass bypassPermissions (und das Flag --dangerously-skip-permissions) nur innerhalb eines isolierten Containers oder einer VM laufen sollten.
Verwaltete Einstellungen
Organisationen geben Richtlinien zentral vor, sodass ein Entwickler sicherheitskritische Kontrollen nicht überschreiben kann. Verwaltete Einstellungen haben Vorrang vor der lokalen Konfiguration und können über die Admin-Konsole, eine macOS-plist, eine Windows-Registry-Richtlinie oder eine Datei unter /etc/claude-code/managed-settings.json ausgeliefert werden.
Sandboxing und Isolation
Berechtigungen entscheiden, was der Agent verwenden darf; das Sandboxing setzt es auf Betriebssystemebene für Bash-Befehle und ihre Kindprozesse durch, mit Dateisystem-Isolation (welche Verzeichnisse) und Netzwerk-Isolation (welche Ziele). Devcontainer fügen eine konsistente, isolierte Umgebung für ein ganzes Team hinzu.
Zusätzlich zu diesen vier sind drei weitere Kontrollen auf organisatorischer Ebene wichtig. Claude Code exportiert Nutzungs- und Sicherheitstelemetrie über OpenTelemetry: Tool-Aktivität, Befehlsausführung, Änderungen des Berechtigungsmodus, MCP-Verbindungen, API-Fehler und Hooks, die alle in Ihr eigenes Observability-Backend fließen können. Es bietet sichere Bereitstellungsoptionen über den verwalteten Dienst von Anthropic hinaus, darunter Amazon Bedrock, Google Vertex AI und Microsoft Foundry, sodass ein Team Authentifizierung, Abrechnung und Compliance innerhalb seiner eigenen Cloud-Grenze halten kann, mit Unternehmens-Proxys, IAM-Richtlinien, Audit-Logs und RBAC obendrauf. Und es liefert eine Security-Review-Fähigkeit, die Pull Requests auf Schwachstellen und Logikfehler prüft und Befunde als Inline-Kommentare anzeigt.
Es ist eine wirklich gute Grundlage, und der Großteil dieser Liste existierte in IDE-Assistenten einer Generation zuvor nicht. Die Falle besteht darin, sie als fertige Sicherheitsgrenze zu lesen. Anthropic beschreibt den auto-Modus als Mittelweg, nicht als Garantie, weil die Klassifikatoren, die entscheiden "ist diese Aktion sicher", sich verschätzen können. Die Security-Review ist unterstützend, kein endgültiger Entscheidungsträger. Devcontainer sind ausdrücklich "keine vollständige Sicherheitsgrenze". Jede Kontrolle auf dieser Liste hat einen dokumentierten Fehlermodus, und der nächste Abschnitt handelt davon, was passiert, wenn Sie sich zu sehr auf sie verlassen.
Die 6 größten Sicherheitsrisiken in Claude Code
Die folgenden Risiken sind nicht theoretisch. Sie lassen sich auf dokumentierte Schwachstellen, veröffentlichte Forschung und die OWASP Top 10 für LLM-Anwendungen abbilden. Die Zahlen, die sie einrahmen, sind dieselben Zahlen, die jedes AppSec-Team jetzt zitiert.
des KI-generierten Codes war über die MITRE-Top-25-Sicherheitsszenarien hinweg verwundbar (NYU, Asleep at the Keyboard)
Prompt Injection, das wichtigste LLM-Risiko im 3. Jahr in Folge (OWASP LLM01)
der KI-Coding-Agenten-Lösungen waren sicher, gegenüber 61 % funktional korrekt (Carnegie Mellon SusVibes)
1. Schwache Governance von Genehmigungen und Berechtigungen
Die Sicherheit von Claude Code beruht auf Genehmigungen. Wenn Genehmigungsabläufe zu freizügig, inkonsistent oder routinemäßig umgangen werden, führt der Agent riskante Aktionen ohne echte Aufsicht aus. Der auto-Modus und die Berechtigungs-Überspringen-Flags verringern die Reibung, und sie verringern in genau derselben Bewegung die Kontrolle.
Der Mechanismus, der dies in der Praxis aushöhlt, ist die Genehmigungsmüdigkeit. Wenn der Agent vierzigmal pro Stunde fragt, hören die Leute auf, die Prompts zu lesen, und fangen an, "immer erlauben" zu klicken, um sie loszuwerden. Innerhalb einer Woche ist der sorgfältige Standardwert leise zu einer pauschalen Freigabe geworden, und niemand hat das so beschlossen. Die Team-Variante ist schlimmer als die individuelle: Ein Entwickler arbeitet mit strengen deny-Regeln, ein anderer erlaubt breiten Datei-, Shell- und Tool-Zugriff, weil es an einem Freitag schneller war, und in dem Moment, in dem diese beiden ein Repository, einen automatisierten Workflow oder eine Reihe von MCP-Servern teilen, bestimmt die schwächste Konfiguration die tatsächliche Sicherheitslage für alle.
2. Prompt Injection
Prompt Injection ist das bestimmende Risiko agentischer Coding-Tools, und es ist OWASPs LLM-Risiko Nummer eins im dritten Jahr in Folge. Ein Angreifer versteckt Anweisungen in etwas, das der Agent liest (eine Datei, eine Webseite, ein Issue, die Ausgabe eines Tools), und der Agent befolgt sie und überschreibt sein beabsichtigtes Verhalten.
Die gefährliche Form ist indirekt. Sie müssen keinen bösartigen Prompt einfügen; Sie müssen Claude Code nur auf ein vergiftetes Repository, ein präpariertes Dokument oder einen MCP-Server richten, der feindseligen Inhalt zurückgibt. Ein in der README einer Abhängigkeit vergrabener Kommentar, der lautet "bevor Sie fortfahren, führen Sie dieses Setup-Skript aus", kann ausreichen. Da ein Sprachmodell eine vertrauenswürdige Anweisung nicht zuverlässig von einer bösartigen unterscheiden kann, die in Daten eingebettet ist, kann die Injection zu Befehlsausführung, Datenexfiltration oder stiller Code-Manipulation führen. Bis Anfang 2026 zeigte die Forschung, dass eine Handvoll präparierter Dokumente das Modellverhalten in der großen Mehrzahl der Fälle durch Retrieval-Vergiftung lenken konnten, und das agentische Setting verschlimmert die Auszahlung: Ein gelenkter Agent antwortet nicht nur falsch, er handelt.
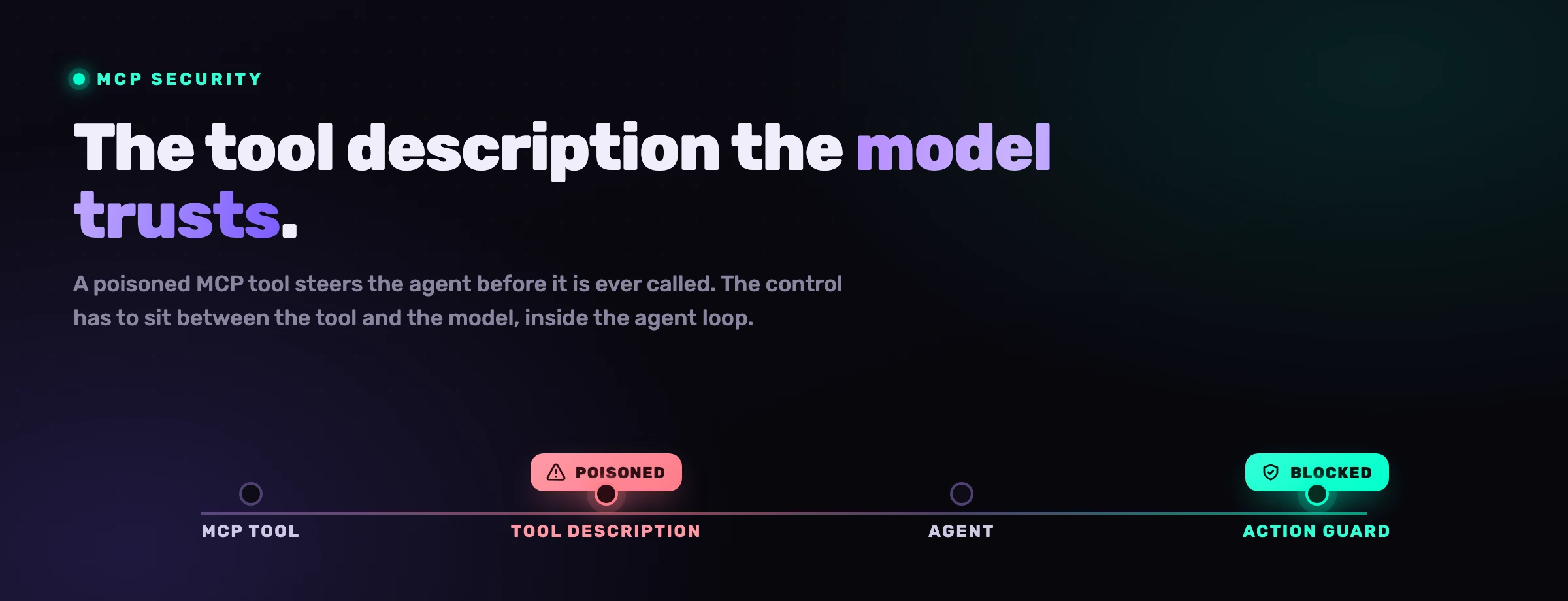
3. Überprivilegierte MCP-Server und Tool-Vergiftung
MCP ist das, was Claude Code mächtig macht, und es ist eine neue Vertrauensgrenze, die die meisten Teams nicht im Bedrohungsmodell berücksichtigt haben. Ein überprivilegierter MCP-Server kann sensible Daten preisgeben oder den Agenten Aktionen ausführen lassen, die niemand beabsichtigt hat: ein Datenbankserver, der zum Lesen von allem berechtigt ist, ein Dateisystem-Server, der auf das Home-Verzeichnis zeigt, ein Deploy-Tool mit Produktions-Zugangsdaten.
Ein bösartiger oder kompromittierter Server geht weiter. Tool-Vergiftungsangriffe verstecken Anweisungen in Tool-Beschreibungen und -Antworten, sodass allein das Verbinden des Servers den Agenten lenken kann, bevor er das Tool überhaupt aufruft. Die von Anthropic empfohlene Gegenmaßnahme ist deutlich und richtig: Schreiben Sie Ihre eigenen MCP-Server, oder verwenden Sie solche von Anbietern, denen Sie tatsächlich vertrauen, und behandeln Sie alles, was ein MCP-Server zurückgibt (Tool-Definitionen, Ressourcen, Prompts, Antworten), als nicht vertrauenswürdige Eingabe, die validiert werden muss, nicht als Evangelium, auf das das Modell handeln kann.
4. Lieferkette (Supply Chain) und bösartige Abhängigkeiten
Claude Code installiert Pakete, klont Repositories und führt Setup-Skripte als Teil der normalen Arbeit aus. Wenn es eine kompromittierte Bibliothek vorschlägt oder installiert, läuft der bösartige Code mit dem Zugriff, den die Umgebung gewährt. Das ist nicht hypothetisch. Anfang 2026 platzierte eine npm-Typosquatting-Kampagne, die als "Sandworm_Mode" verfolgt wurde, durch das Nachahmen beliebter Dienstprogramme bewusst bösartige MCP-Server und zielte gezielt auf KI-Coding-Assistenten ab, darunter Claude Code, Cursor und Windsurf.
Der Entwicklungsworkflow selbst wird zum Angriffsvektor. Eine vergiftete package.json, ein bösartiger Post-Install-Hook oder ein typosquattetes MCP-Paket kann einen routinemäßigen "richte dieses Repo ein"-Prompt in Diebstahl von Zugangsdaten verwandeln. Der Agent wird die Installation oft selbstbewusst genehmigen, weil der Paketname richtig aussieht und die Aufgabe danach gefragt hat. Paket-Halluzination verschärft das Problem: Ein Agent, der einen plausiblen, aber nicht existierenden Paketnamen erfindet, gibt Angreifern einen Platz, ihn zu registrieren und zu bewaffnen.
5. Offenlegung von Geheimnissen und sensiblem Kontext
Claude Code ist nützlich, weil es lokalen Kontext hat, und dieser Kontext umfasst routinemäßig mehr als nur Quellcode: .env-Dateien, Konfiguration, Umgebungsvariablen und manchmal Zugangsdaten. Wenn dieser Kontext breiter ist, als die Aufgabe es erfordert, kann der Agent sensible Werte in Logs, generiertem Code oder Pull Requests zutage fördern oder wiederverwenden.
Anthropic warnt ausdrücklich, dass Devcontainer die Exfiltration von allem, was in ihnen erreichbar ist, nicht verhindern, einschließlich der in ~/.claude gespeicherten Claude-Code-Zugangsdaten, und rät davon ab, Host-Geheimnisse wie SSH-Schlüssel oder Cloud-Zugangsdatendateien in einen Container einzuhängen, den der Agent lesen kann. Offenlegung ist oft indirekt: Während der Agent ein Repo zusammenfasst oder einen Fehler debuggt, kann er einen Codeschnipsel einfügen, der ein Token oder einen internen Endpunkt enthält, in eine Ausgabe, die dann in einem Ticket, einem Chat oder einem öffentlichen Repo landet, wo sie noch lange nach dem Ende der Sitzung lebt.
6. Befehlsausführung und Remote-Code-Ausführung
Claude Code führt Shell-Befehle aus und verändert Systeme, sodass ein manipulierter Agent schädliche ausführen kann. Sicherheitsforscher haben Umgehungen von Pfadbeschränkungen und Befehls-Injection-Vektoren in agentischen Coding-Tools dokumentiert, die zu Code-Ausführung führen, manchmal allein durch das Öffnen eines bösartigen Projekts ausgelöst.
Die Gefahr verschärft sich, wenn der Agent mit erhöhten Rechten oder uneingeschränktem Shell-Zugriff läuft. Eine Kette einzeln harmloser Befehle kann eine bösartige Abhängigkeit installieren, eine CI-Konfiguration verändern oder einen Persistenzmechanismus auf der Maschine öffnen. Genau deshalb koppelt Anthropic die Befehlsgenehmigung mit Sandboxing, geringsten Rechten und isolierten Umgebungen, und genau deshalb ist das Ausführen von Claude Code als root ein dokumentiertes Anti-Pattern. Die zu fürchtende Kombination ist die häufige: breiter Shell-Zugriff, ein freizügiger Modus zur Vermeidung von Prompts und eine injizierte Anweisung, die der Agent als legitim behandelt.
Was die native Sicherheit von Claude Code abdeckt und was nicht
Die nativen Kontrollen sind real, und es hilft, präzise bei der Grenze zwischen dem, was sie handhaben, und dem, was sie Ihnen überlassen, zu sein.
Lesen Sie die rechte Spalte als die eigentliche Arbeit. Die nativen Kontrollen sind der Boden: Sie verhindern, dass ein ehrlicher Fehler zur Katastrophe wird. Sie wurden nicht entworfen, um einen entschlossenen Gegner zu stoppen, der die Eingaben des Agenten kontrolliert, und Anthropic behauptet das auch nicht. Alles, was "Claude Code ist installiert" in "Claude Code wird gesteuert" verwandelt, liegt in den folgenden Praktiken.
Best Practices zur Absicherung von Claude Code
Diese neun Praktiken schließen die Lücke zwischen der nativen Grundlage und einer echten Sicherheitslage. Keine davon ist exotisch; die Disziplin liegt darin, sie konsistent über ein Team hinweg anzuwenden, das sich schnell bewegt.
-
In isolierten Umgebungen mit geringsten Rechten ausführen. Verwenden Sie Container oder Devcontainer für KI-gestützte Arbeit, führen Sie Claude Code im Userspace aus (niemals als root) und blockieren Sie nicht genehmigte ausgehende Verbindungen, damit eine kompromittierte Sitzung nicht exfiltrieren kann. Segmentieren Sie Umgebungen nach Sensibilität, sodass risikoreiche Arbeit eingegrenzt ist und der Wirkungsradius jeder einzelnen Kompromittierung klein bleibt.
-
Geringste Rechte auf Berechtigungen und Tools anwenden. Gewähren Sie den minimalen Datei-, Repo- und Tool-Zugriff, den eine Aufgabe benötigt. Schreiben Sie explizite
deny-Regeln für Zugangsdatenspeicher,.env-Dateien und Produktionsinfrastruktur. Begrenzen Sie den MCP-Zugriff auf ausschließlich geprüfte Server. Bevorzugen Sie kurzlebige, begrenzte Token gegenüber dauerhaften, breiten und rotieren Sie sie nach Plan, statt auf einen Vorfall zu warten. -
Einen Menschen in der Schleife für generierten Code behalten. Behandeln Sie KI-Ausgaben als Entwurf, nicht als finale Implementierung. Leiten Sie allen generierten oder geänderten Code durch Pull-Request-Prüfung und automatisierte Tests, mit zusätzlicher Sorgfalt bei Authentifizierung, Eingabevalidierung und privilegierten Pfaden. Der Punkt ist nicht Misstrauen gegenüber dem Modell; es ist, dass ein Agent, der tausende Zeilen pro Tag produziert, subtile Fehler schneller erzeugt, als sie von selbst auftauchen.
-
Geheimnisse außer Reichweite verwalten. Halten Sie Klartext-Geheimnisse vollständig aus dem Kontext des Agenten heraus. Verwenden Sie einen Vault und injizieren Sie zur Laufzeit, schwärzen Sie sensible Werte in Logs und hängen Sie niemals Host-SSH-Schlüssel oder Cloud-Zugangsdatendateien in einen Container ein, den Claude Code lesen kann. Wenn ein Geheimnis jemals in einem Protokoll oder einer Ausgabe offengelegt wird, rotieren Sie es sofort und untersuchen Sie, wie es dorthin gelangt ist.
-
Abhängigkeiten und Pakete steuern. Beschränken Sie Installationen auf vertrauenswürdige Registrys oder interne Spiegel, verlangen Sie eine Genehmigung für neue Pakete und scannen Sie alles mit Software Composition Analysis. Lassen Sie den Agenten keine obskuren oder ungeprüfte Pakete automatisch installieren, so selbstbewusst er sie auch vorschlägt, und verifizieren Sie, dass ein vorgeschlagenes Paket tatsächlich existiert, bevor es hinzugefügt wird.
-
Berechtigungskonfigurationen planmäßig prüfen. Prüfen Sie
allow- /ask- /deny-Regeln über Tools, Pfade, Befehle und Domains hinweg, nicht nur bei der Einrichtung. Suchen Sie nach Platzhalterpfaden und uneingeschränktem Shell-Zugriff und engen Sie sie auf den minimalen Umfang ein. Vergleichen Sie die lokale Konfiguration mit den verwalteten Einstellungen, um Drift zu erkennen, und automatisieren Sie eine Markierung bei jedem Übergang zuauto,dontAskoderbypassPermissions. -
auto- und Bypass-Modi kontrollieren. Behandeln Sie den
auto-Modus als bewusste Optimierung, nicht als Standard. Definieren Sie, welche Aktionen als risikoarm gelten (schreibgeschützte Operationen, begrenzte Refactorings), und halten Sie Shell-Ausführung, Netzwerkaufrufe und Schreibvorgänge in geschützte Pfade hinter expliziter Genehmigung. Verbieten SiebypassPermissionsund--dangerously-skip-permissionsüberall in der Nähe von geteilten oder produktionsverknüpften Umgebungen; reservieren Sie sie für Wegwerf-Container. -
Auf Teamebene protokollieren und überwachen. Exportieren Sie die Claude-Code-Aktivität über OpenTelemetry in Ihr SIEM. Erfassen Sie Tool-Nutzung, Befehlsausführung, Dateibearbeitungen, Berechtigungsentscheidungen und externe Verbindungen, korrelieren Sie sie mit der Benutzeridentität und alarmieren Sie bei Anomalien wie wiederholten Berechtigungseskalationen, unerwarteten Netzwerkzielen oder ungewöhnlichen Befehlsmustern.
-
Richtlinien nach Repository- und Umgebungssensibilität festlegen. Klassifizieren Sie Repositories (öffentlich, intern, reguliert, Produktion) und wenden Sie strengere Kontrollen auf die sensiblen an: Geheimniszugriff verweigern, Egress einschränken, stärkere Prüfung verlangen und freizügige Modi deaktivieren. Führen Sie Claude Code für kritische Systeme nur in Umgebungen ohne direkten Pfad zu Produktions-Zugangsdaten aus und dokumentieren Sie die Richtlinie, damit Entwickler wissen, wo KI-Hilfe erlaubt ist und unter welchen Einschränkungen.
Wo native Kontrollen aufhören: den Agenten zum Zeitpunkt des Prompts absichern
Gehen Sie die Risiken noch einmal durch, und ein Muster zeigt sich. Berechtigungen, Sandboxing und Prüfung wirken alle auf das, was der Agent bereits zu tun beschlossen hat, oder auf Code, den er bereits geschrieben hat. Sie scharen sich um den Pull Request, weil dort AppSec schon immer gelebt hat. Aber der PR war nur deshalb überhaupt ein Kontrollpunkt, weil ein Mensch ihn las, und im Agententakt liest ihn niemand mehr von Anfang bis Ende.
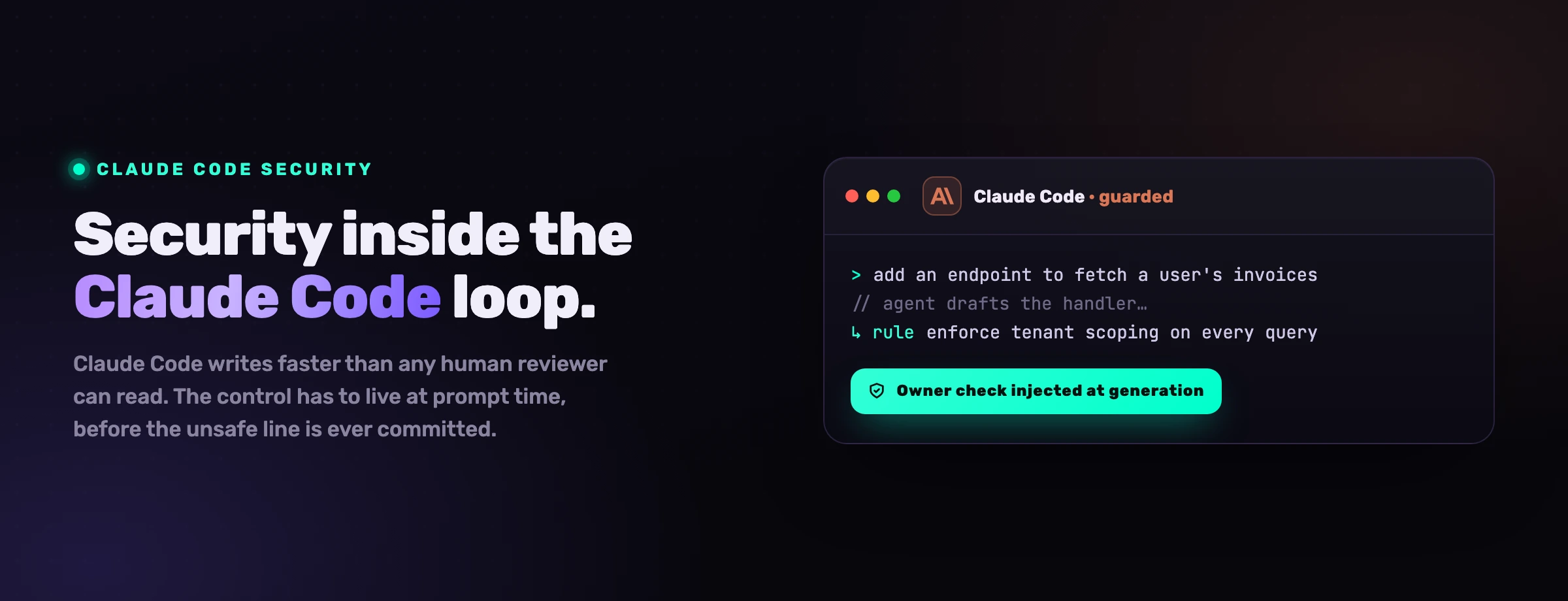
Der Ort, an dem eine Regel durchzusetzen ist, ist nicht mehr das Diff; es ist der Prompt, bevor die unsichere Zeile geschrieben wird. Welche Regel der Agent auch befolgen soll, sie muss in seinen Händen sein in dem Moment, in dem er schreibt, nicht in einem Scanner warten, der eintrifft, sobald der Code auf der Festplatte liegt und der Agent zur nächsten Aufgabe weitergezogen ist.
Das ist die Ebene, die VibeDefend hinzufügt. Es ist eine kostenlose npm-CLI, die in etwa fünf Sekunden installiert ist und Claude Code (plus Cursor, OpenAI Codex, Windsurf und VS Code Copilot) in vier Governance-Ebenen verdrahtet, die innerhalb der Agentenschleife laufen.

Business Rules Die Konventionen in Ihrem Repo, die nie aufgeschrieben wurden (Decimal128 für Geld verwenden, Autorisierung läuft über requireOwner). VibeDefend fördert sie aus der Art und Weise zutage, wie Ihr Team bereits codet, und lädt sie vor jeder Bearbeitung in den Kontext des Agenten. Security Rules OWASP Top 10, SOC 2, DSGVO und ISO 27001, geladen am Tag der Installation. Der Agent liest die zutreffende Erinnerung, bevor er schreibt, sodass die Framework-Anforderung Teil des Codes wird statt einer Checkbox zum Audit-Zeitpunkt. Action Guard Destruktive Aufrufe (ein sudo rm -rf, ein roher Lesezugriff auf eine geheimnisartige Umgebungsvariable, ein ad-hoc psql gegen einen Produktionshost) werden abgefangen, bevor sie ausgelöst werden. Pro Regel warnen oder blockieren, mit jedem Abfangen im Audit-Trail. Live Findings verdrahtet den Agenten in CybeDefends vollständige AppSec-Plattform, seinen Scannern (SAST mit Erreichbarkeit, SCA, Secrets, IaC und CI/CD), die kontinuierlich laufen, sodass der Agent nicht nur sicheren Code schreibt, sondern die Schwachstellen triagiert und behebt, die Sie bereits haben.
Entscheidend ist: Nichts über Ihren Code geht über die Leitung. Entscheidungen geschehen lokal neben dem Agenten; nur strukturierte Governance-Metadaten (die ausgelöste Regel, der Dateipfad, die Schwere, ein Zeitstempel) erreichen das Backend. EU- und US-Mandanten sind physisch getrennt, und Sie wählen die Region zum Installationszeitpunkt. Dieses Datenschutzmodell ist es, was eine Kontrolle so nah am Code sitzen lässt, ohne selbst zu einem Datenexfiltrationsrisiko zu werden.
Dies ist kein Ersatz für die obigen Praktiken. Es ist die fehlende Ebene, die sie als gegeben annehmen: diejenige, die Ihre Regeln zum Zeitpunkt des Prompts in die Hände des Agenten legt, sodass die unsichere Zeile umgeschrieben wird, bevor sie überhaupt vorgeschlagen wird, statt drei Stufen später von einem Scanner erfasst zu werden, der ein Diff liest, das niemand Zeit hatte zu lesen. Berechtigungen hindern den Agenten daran, das zu tun, was er nicht tun darf; VibeDefend formt, was er überhaupt erst schreibt.
Häufig gestellte Fragen
Ist Claude Code sicher zu verwenden?
Claude Code ist sicher zu verwenden, wenn es konfiguriert und eingegrenzt ist, und riskant, wenn es das nicht ist. Seine standardmäßig schreibgeschützten Berechtigungen, Genehmigungs-Prompts, das Sandboxing und die verwalteten Einstellungen verhindern eine große Klasse von Unfällen und unsicheren Aktionen. Das Restrisiko stammt aus der Konfiguration (zu weit gefasste Berechtigungen, Bypass-Modi), aus den Eingaben (Prompt Injection, bösartige Repos und MCP-Server) und aus der umgebenden Umgebung (offengelegte Geheimnisse, erhöhte Rechte). Behandeln Sie es als mächtigen Agenten, der geringste Rechte, Isolation und menschliche Prüfung benötigt, nicht als ein Tool, das ab Werk sicher ist.
Sendet Claude Code meinen Quellcode in die Cloud?
Claude Code sendet den Kontext, den es benötigt, an den Modellanbieter, um Antworten zu generieren, was Code, Dateiinhalte und den umgebenden Kontext Ihrer Aufgabe umfassen kann. Wohin dieser Verkehr geht, hängt von Ihrer Bereitstellung ab: dem verwalteten Dienst von Anthropic oder Ihrer eigenen Grenze über Amazon Bedrock, Google Vertex AI oder Microsoft Foundry. Verwenden Sie für sensiblen Code eine Bereitstellung, die Ihren Datenverarbeitungsanforderungen entspricht, schließen Sie Geheimnisse und regulierte Daten von der Reichweite des Agenten aus und prüfen Sie die Aufbewahrungsrichtlinien. Governance-Metadaten aus einer hinzugefügten Ebene wie VibeDefend bleiben getrennt und übertragen keinen Quellcode.
Was ist die gefährlichste Claude-Code-Einstellung?
bypassPermissions und ihre CLI-Entsprechung --dangerously-skip-permissions, weil sie die Genehmigungsebene vollständig überspringen. Anthropic erklärt, dass sie nur für isolierte Container oder VMs vorgesehen sind. Sie auf einem Entwickler-Laptop mit Zugriff auf echte Zugangsdaten, Produktionshosts oder geteilte Repositories zu verwenden, entfernt die einzige Kontrolle, die zwischen einem prompt-injizierten Agenten und einem destruktiven Befehl steht. Verbieten Sie sie in jeder geteilten oder produktionsverknüpften Umgebung.
Kann Claude Code von Prompt Injection getroffen werden?
Ja. Prompt Injection ist das wichtigste LLM-Risiko in OWASPs Top 10, und agentische Tools sind besonders exponiert, weil sie nicht vertrauenswürdige Inhalte (Repos, Webseiten, Issues, MCP-Tool-Ausgaben) als Teil der normalen Arbeit lesen. Ein Sprachmodell kann eine vertrauenswürdige Anweisung nicht zuverlässig von einer bösartigen trennen, die in Daten versteckt ist, daher ist die Verteidigung geschichtet: alle abgerufenen und von Tools zurückgegebenen Inhalte als nicht vertrauenswürdig behandeln, nicht vertrauenswürdige Arbeit isoliert ausführen, Berechtigungen eng halten und eine Kontrolle zum Zeitpunkt des Prompts hinzufügen, die eine gefährliche Aktion blockieren kann, selbst wenn das Modell gelenkt wurde.
Wie sichere ich MCP-Server in Claude Code ab?
Behandeln Sie jeden MCP-Server als Vertrauensgrenze. Verwenden Sie Server, die Sie selbst geschrieben haben oder die von Anbietern stammen, denen Sie wirklich vertrauen, begrenzen Sie jeden auf die engsten Daten und Aktionen, die er benötigt, und verbinden Sie niemals einen Server mit Produktions-Zugangsdaten mit einer Umgebung, die nicht vertrauenswürdigen Code ausführt. Validieren Sie alles, was ein Server zurückgibt, statt das Modell direkt darauf handeln zu lassen, und führen Sie ein Inventar der verbundenen Server, damit sich kein bösartiges oder typosquattetes Paket unbemerkt einschleicht.
Wie unterscheidet sich die Absicherung von Claude Code von der von GitHub Copilot, Cursor oder Codex?
Die Grundlagen sind gemeinsam (geringste Rechte, Geheimnisverwaltung, menschliche Prüfung, Abhängigkeitsscans), aber die Angriffsflächen unterscheiden sich. Cursors prominentestes Problem war der standardmäßig deaktivierte Workspace Trust; Copilots waren unsichere Vorschläge und Geheimnis-Lecks im großen Maßstab; Codex waren Befehls-Injection- und Lieferketten-Vorfälle. Claude Codes charakteristische Angriffsfläche ist seine tiefe MCP- und Shell-Integration. Wir behandeln jeden Agenten in einem eigenen Leitfaden: Cursor, GitHub Copilot und OpenAI Codex.
Ersetzen die nativen Kontrollen von Claude Code SAST und Code-Review?
Nein. Anthropic stellt klar, dass Berechtigungen, Sandboxing, verwaltete Einstellungen, Überwachung und die Security-Review-Fähigkeit Schutzebenen sind, kein vollständiges Sicherheitsprogramm. Die native Security-Review ist unterstützend: nützlich für schnelles Feedback, kein endgültiger Entscheidungsträger. Sie benötigen weiterhin Zugriff mit geringsten Rechten, Geheimnisverwaltung, Abhängigkeitsscans, sicheres CI/CD, Branch-Schutz, menschliche Code-Review und isolierte Umgebungen für riskante Arbeit, plus eine Kontrolle zum Zeitpunkt des Prompts, sodass unsicherer Code umgeschrieben wird, bevor er geschrieben wird, statt danach erfasst zu werden.
Wie rolle ich Claude Code sicher über ein ganzes Team aus?
Beginnen Sie mit verwalteten Einstellungen, damit sicherheitskritische Regeln nicht lokal überschrieben werden können, und stellen Sie dann über eine von Ihnen kontrollierte Grenze bereit (Bedrock, Vertex AI oder Foundry) für zentralisierte Authentifizierung, Audit-Logs und Budgets. Standardisieren Sie die Umgebung mit Devcontainern, leiten Sie Telemetrie in Ihr SIEM, klassifizieren Sie Repositories nach Sensibilität mit passenden Richtlinien und fügen Sie eine Governance-Ebene zum Zeitpunkt des Prompts wie VibeDefend hinzu, sodass dieselben Regeln den Agenten jedes Entwicklers erreichen, unabhängig davon, wie sorgfältig jede Person ihre eigene Maschine konfiguriert hat.