On this page

Open any SAST report on a working codebase. You will see four-digit numbers next to "critical". Open the same scan a week later. The same numbers, give or take. Eventually a security engineer drowns in triage and the team ships anyway. This article is about what is actually happening in those reports, and why most of what you see is not what it claims to be.
The first time you see a SAST tool say "1,247 vulnerabilities", a small voice asks the right question: are there really one thousand two hundred and forty seven exploitable bugs in this repository? You already know the answer is no. What you may not know is exactly why the answer is no, and what would have to be true for the number to mean something.
This is a piece about three filters: reachability, exploitability and business logic. Every static analysis tool worth running has to apply them, in some order. Most of them cheat on at least one. Here is what each filter does, with concrete code, and why pattern matching alone keeps producing four-digit reports a year after a four-digit report makes any team give up.
The 1,200 number is not a SAST bug. It's the design.
A pattern-matching SAST scanner does roughly this: parse the source, walk the AST, and for each node check whether it matches a list of dangerous shapes. eval(x). exec(x). A SQL string with + between literals. An innerHTML = assignment. Each match becomes a finding.
This is fast and language-portable. It also has nothing to do with whether anyone can actually trigger the dangerous shape. When the scanner reports 1,247 findings, what it is really telling you is "I found 1,247 syntactic patterns that could, in principle, be dangerous in some calling context I did not bother to look at."
That last clause is doing a lot of work. Let's take it apart.
Filter one: reachability
A finding is reachable when an attacker can actually run the code that contains it.
Consider this Express handler.
app.post("/admin/migrate", requireAdmin, async (req, res) => {
const { sql } = req.body;
const result = await db.raw(sql); // SAST flags this
res.json(result);
});
A pattern scanner will flag the db.raw(sql) line. SQL injection from user input. Severity: critical. The scanner is not wrong about the shape; it is the shape of a SQL injection. But to exploit it, the request has to make it past requireAdmin. Which means an attacker has to already be an admin. Which means there is no SQL injection here, there is a "we trust admins to not break the database" problem, which is a different conversation.
Reachability says: from any externally controllable entry point (a request, a queue message, a deserialised payload), can data reach this dangerous shape? If the answer is no, the finding is not real, even though the syntactic pattern is.
There are three common ways code is unreachable in this sense:
- Authentication or authorisation gates sit between the entry point and the sink. The middleware short-circuits the dangerous path.
- Sanitisation transforms attacker input before it reaches the sink. A
parseIntthat throws on non-digits. A WHERE clause built from a parameterised query. A framework that auto-escapes HTML. - The function is never actually called from any reachable path. Dead code is a real category and modern codebases are full of it. Old admin tooling. A handler registered on a route that no longer exists. A library function only used by tests.
The honest version of "1,247 findings" looks something like "of which 380 are reachable from at least one externally controllable entry point". You have already cut the queue by two thirds, and you have not even started looking at exploitability.
Filter two: exploitability
Reachable does not mean exploitable. It just means the data path exists.
Take that same db.raw example, with the auth middleware removed:
app.post("/api/search", async (req, res) => {
const { q } = req.body;
const result = await db.raw(
"SELECT id, title FROM articles WHERE title LIKE ?",
[`%${q}%`]
);
res.json(result);
});
The pattern is still there. The path is still reachable from any unauthenticated client. The finding is still "SQL injection". But the bound parameter [\%$%`]means the database will treatqas a value, not as SQL. There is no injection, no matter whatq` contains. The finding is not exploitable.
Exploitability is about how data is shaped between the source and the sink. Three things matter here:
- Encoding boundaries. A WHERE clause built with parameter binding is exploit-safe at the SQL layer. A template engine with auto-escape is exploit-safe at the HTML layer. Pattern scanners do not always see these encoding boundaries because they live in framework method calls (
db.raw(template, params)) rather than in syntactic patterns. - Type narrowing. If a value flows through
parseIntor a Joi schema or a TypeScript type guard before reaching a sink, its shape is constrained. SQL injection requires control over the raw string. A typed integer cannot inject SQL. - Sink semantics.
child_process.exec("ls")is not an injection if the string is a literal.eval(JSON.stringify(x))is harmless even though it contains the wordeval. The sink is dangerous; the call is not.
After this filter, the number drops again. From 380 reachable findings you might be down to 60 actually exploitable. Most teams stop here, declare those 60 the "real" backlog, and start triaging.
This is a mistake. The 60 you have left are CWE bugs. The bugs that hurt are not always CWE bugs.
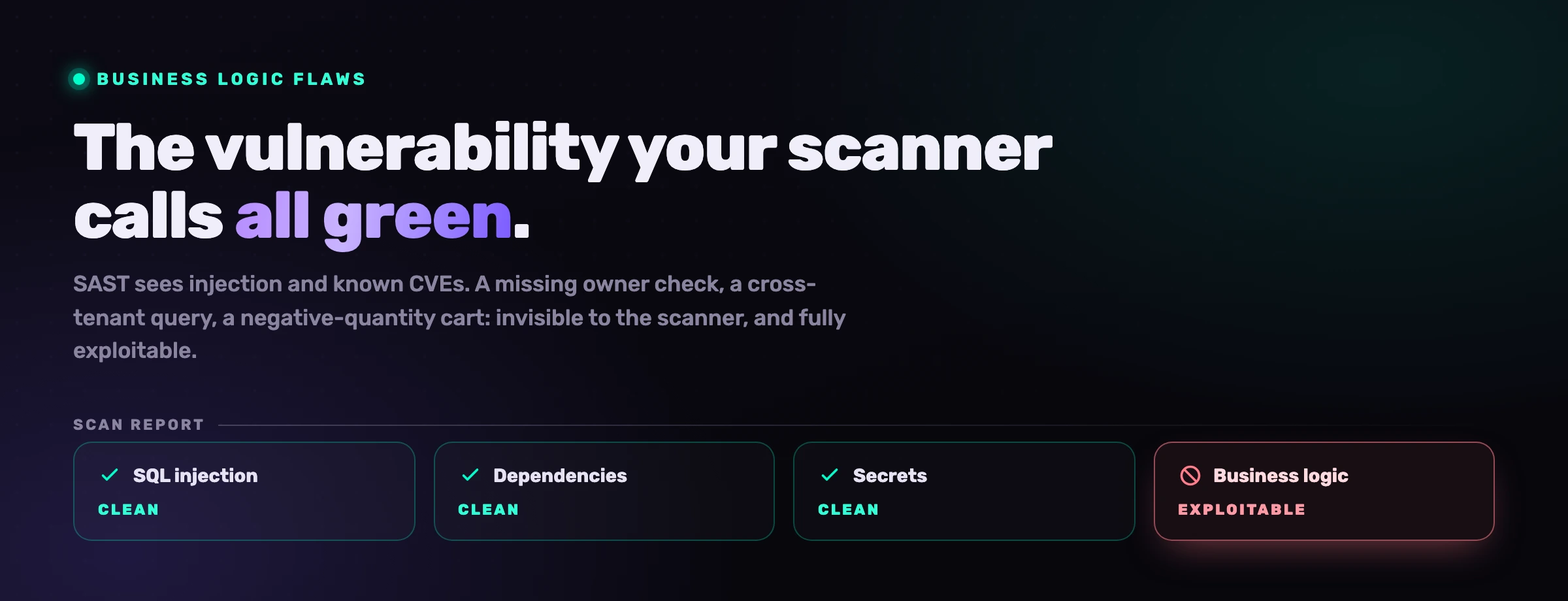
Filter three: business logic
Here is a vulnerability no SAST scanner can flag with pattern matching, no matter how clever:
app.post("/checkout", requireAuth, async (req, res) => {
const { items } = req.body;
let total = 0;
for (const it of items) {
const product = await db.products.findById(it.productId);
total += product.price * it.quantity; // it.quantity can be -1
}
await charge(req.user, total);
await fulfilOrder(req.user, items);
});
Set quantity to -1 and the price subtracts. Stack negative-quantity items against a positive one and the total reaches zero. The charge(0) succeeds. The order ships.
This is not in the OWASP Top 10. It is not a CWE pattern. There is no syntactic shape that says "negative quantities can be exploited"; the shape total += a * b is normal arithmetic. The vulnerability is that the business allows negative quantities through input but the business intends every quantity to be a positive integer. That intent lives in your codebase, in product specs, in tests that nobody wrote. It does not live in a CWE database.
Business logic flaws account for close to half of the breaches that produce real financial loss. Coupon stacking. Privilege escalation through workflow misuse. Race conditions in account state transitions. The scanner that found 1,247 syntactic findings missed every one of these because it was looking at code shape, not at code intent.
To catch them you need rules mined from the codebase itself: "this field is always a positive integer here, here, and here, but the controller does not validate it". That requires reading more than the AST.
So how do you actually get from 1,200 to 12?
The pipeline that produces 12 from 1,200 is not a smarter regex. It is a different shape of analysis altogether. Roughly:
Build a graph of the codebase
Symbols, function calls, type flows, framework gates, route bindings. Not a flat token stream. A graph the analyser can walk.
Walk it for reachability and exploitability
From every entry point, follow the data. Stop at sanitisers, gates, type narrowings. Only the paths that survive the walk are real candidates.
Lift business rules out of the code itself
Mine invariants from the codebase: this field is always positive, this transition is always gated by a payment, this workflow always ends in an audit log. Each invariant becomes a constraint the agent (or the human) must satisfy.
The first step is what most modern SAST products call a "code property graph", or a knowledge graph. Building one is hard. Walking it is harder. But it is the only honest way to answer "is this finding real" without making a security engineer read your entire codebase.
The 12 that survive all three filters are the ones worth a Jira ticket. The 1,235 that did not survive are not "false positives" in any moral sense; they are syntactic patterns the scanner could not rule out without a graph. If your scanner does not have a graph, you get the full 1,247 every Monday.
Why this matters more in 2026 than it did in 2022
In 2022, the 1,247-finding report was annoying. A security engineer triaged it slowly, nobody enjoyed it, but the codebase grew at human pace and so did the queue.
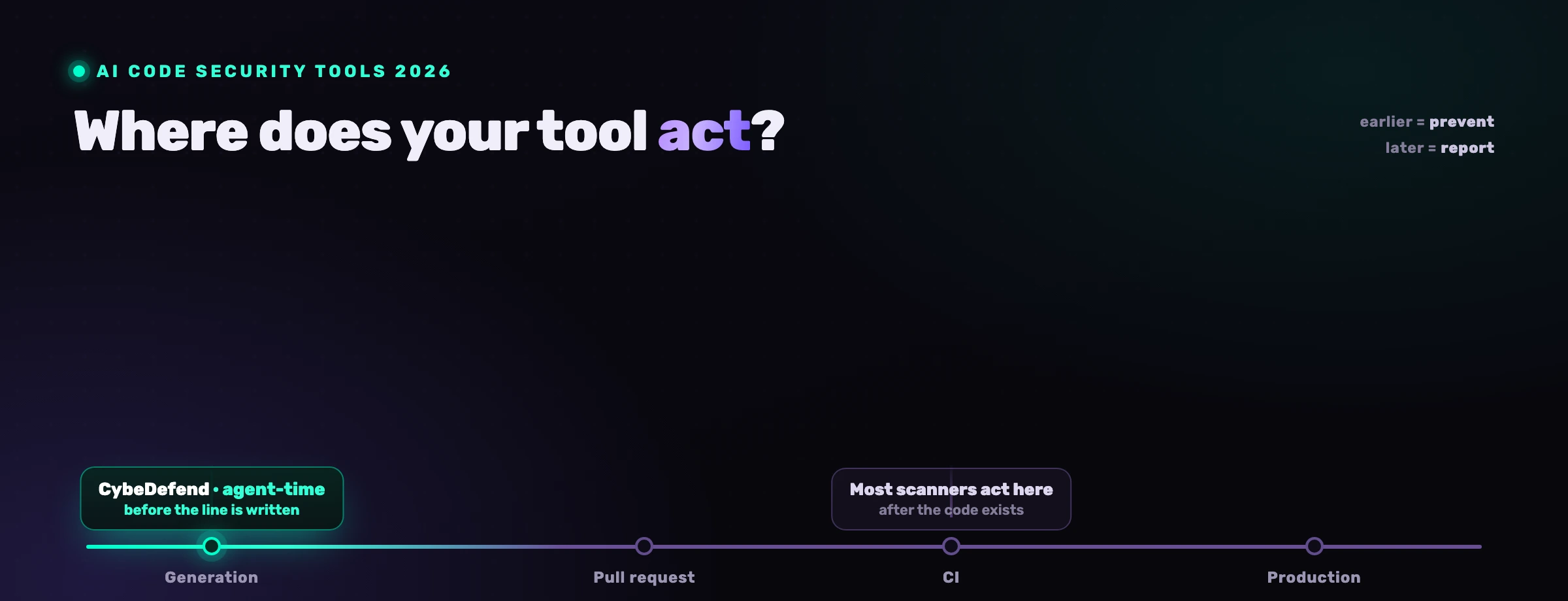
In 2026 the codebase grows at agent pace. AI coding agents now write a meaningful share of every line that lands in production. They produce code in patterns the agent recognises, not in patterns the security engineer recognises. The 1,247 number scales with the velocity of writing, not with the velocity of triage.
You have two options. Either the analysis gets dramatically smarter (graph-based, filtered by reachability and exploitability and business logic before findings are emitted) or the queue eats you. There is no third option where a human reads it all.
A small footnote
We built CybeDefend around this idea. The architecture is a code knowledge graph plus a business-logic mining layer (we call it BLSA) plus an inline interface so the analyser runs while the agent is writing, not after the merge. If you read this far and want to see the same three filters running on your own repo, the install-free path is the fastest read on what your real backlog looks like; thirty minutes from clone to the first verdict, no card required.
The number on the report is not the number of bugs. It is the number of patterns the scanner could not rule out without doing more work. The teams that win are the ones whose scanner does the work.